背景介绍
「得到锦囊」产品刚上线时,该版块首页的最热排序暴露了两个问题:分页时数据重复和最热榜单被霸屏,本文将围绕解决这两个问题来展开,介绍下如何参考牛顿冷却定律来优化最热内容的排序。
“牛顿冷却定律”本质上它描述了高于周围温度的物体会向外散热,并逐渐降温的过程,同时单位时间内散热与周围温差会成正比关系。通过建立”温度”与”时间”之间的函数关系,构建一个”指数式衰减”(Exponential decay)的过程。
如果我们把”热文排名”想象成一个”自然冷却”的过程,那么如下的场景是成立的:
- 任一时刻,网站中所有的文章,都有一个”当前温度”,温度最高的文章就排在第一位。
- 随着时间流逝,所有文章的温度都逐渐”冷却”。
一、最热榜单暴露的问题
2020年1月初,得到App的新产品「得到锦囊」正式上线。产品刚上线时,版块首页的最热排序模块,暴露出了两个问题:分页时数据重复和最热榜单被霸屏,本文将围绕解决这两个问题来展开。
排序规则与朴素的实现方案
产品需求定义的最热排序规则是:按照问题的总查看量来倒序排列,且有分页和查询条件。服务端对于这种场景,最简单高效的实现方式,就是利用sql的query语句了,于是我们就直接 [order by {问题的查看量} desc] 来实现了。
总查看数 = 获得查看权益的用户数 = 购买数 + 赠一得一领取数
这个简单朴素的实现方式,在加上缓存策略,使得我们用较小的成本就满足了产品需求,也应对了较高的流量。

得到锦囊(原问答)的产品定位,和知乎、头条的不太一样,不仅对于提问的内容进行严格审核,对于老师们的解答内容也是会按照标准来品控,所以我们上新的速度并不会很快。等未来发布的问题数量大了以后,肯定是会启用基于大数据的个性推荐算法的,但是摆在眼前的两个问题,必须要尽快解决。
说明:在2020-03月底的版本中,【得到问答】正式改名为【得到方案】。在2020-04月初的版本中【得到方案】改名为【得到锦囊】,为用户提供更为全面的知识服务。时间和精力的关系,本文中的一些文字和图片不进行全量更新了。
问题一 : 分页时会出现重复数据
分页时数据重复,在性质上是个bug,得优先解决。
利用sql的order by 和 limit 对行数据进行排序和分页时,最正确的姿势的是基于至少一个固定的字段值。排序值变化频繁,db加载下一页数据的时候如果上一页某条行记录的排序值发生了变化,就很可能会导致上一页中出现过的记录在下一页再次出现。我们最热排序的依据【总查看数】就是个变化频繁的值,加上我们对每页的结果数据都使用了缓存策略,使得数据在不同的页面出现的几率加大。
通过一些算法策略的调整,比如缓存的key值和查询条件增加了时间窗口,我们降低了数据被重复展现的概率,低到用户几乎无察觉,低到让自己也以为彻底解决了问题。
上新的内容接近百条的时候,新的问题暴露了。春节前的某一天,老板、产品经理、运营都分别吐槽了“最热榜单被霸屏”的问题,希望能有所优化,每天能呈现不同的热点内容 。于是,我们调整了排序语句,在其中加入了最近被查看时间的参数,踩着“知识春晚封版”最后上线的时间点完成了上线。很有效,最热榜单活了,每个小时都会变化,很多问题都有了更多露脸的机会,包括在多个页面反复露脸……
数据重复的几率增高了,高到产品经理和测试都发现了,居然还录屏为证 (ಥ﹏ಥ)
如下是其中的一个实例截屏,我们能看到问题《28岁码农,不想做管理岗,又担心以后失去竞争力,怎么办?》在两个页面出现。
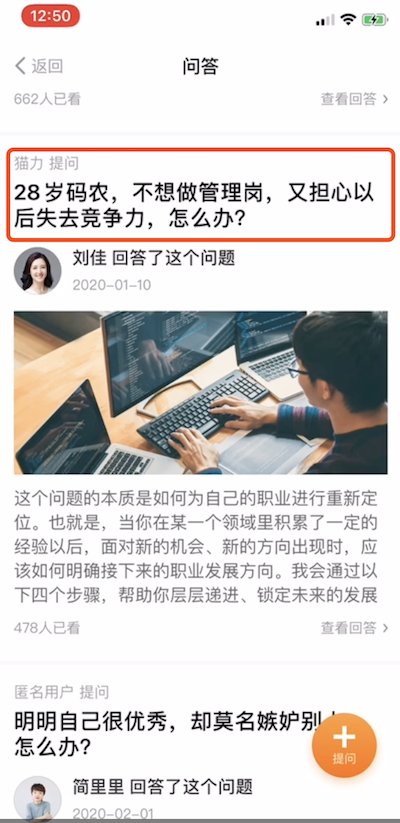
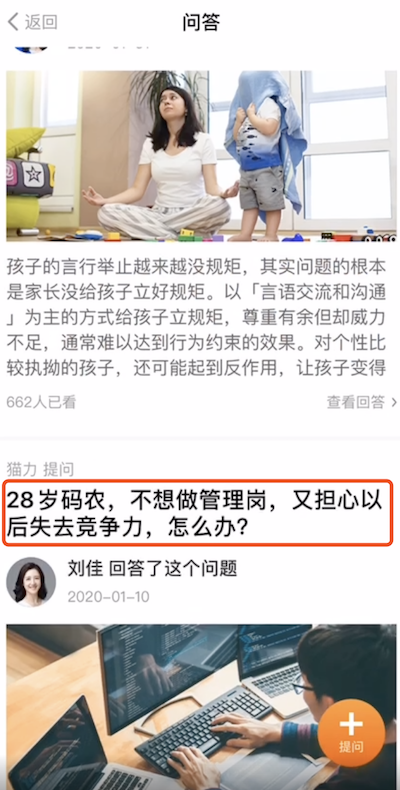
问题二 : 最热榜单被霸屏
我们的新内容是以每天5~10个的频率来发布上线的,用户对于内容的喜好和曝光率会直接影响被查看的数量和排序。
产品上线没多久,排名靠前的榜单就被上线较早且又被关注较多的几条问题占据了,后面新上线的问题,曝光的机会很低。如果按照刚上线时的排序算法,下面几条问题几乎会持续霸屏:
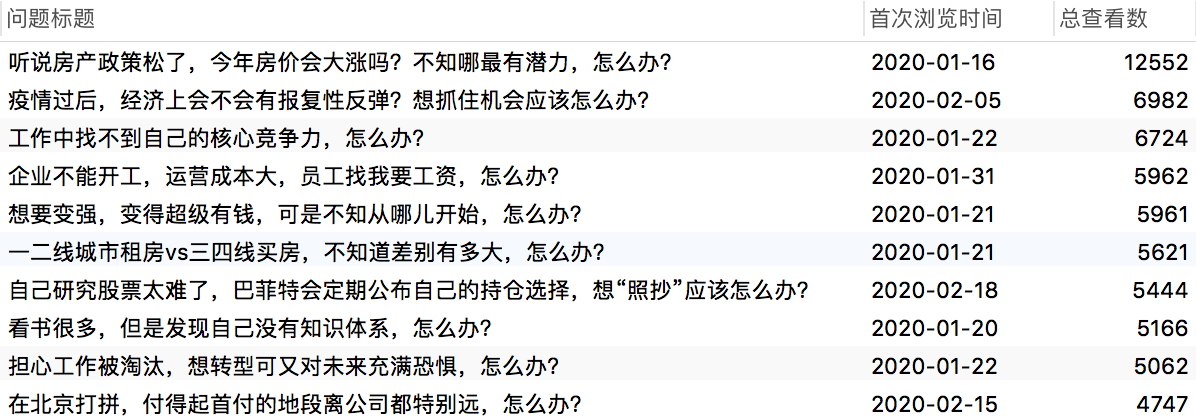
我们的运营发起了一些专题的促销活动,才足以打破了上面的局面。但是,我们是不能对每个问题方案都进行运营活动来拉动销量,更多的还是顺其自然,交给用户去选择,让内容靠实力去竞争。
“长尾效应”的理论告诉我们,非热点内容的累计销售数量,一定是高于几条热点内容的累计销售数量的,所以我们要解决被霸屏的现象,让更多的内容能够有机会登上热榜去“抛头露面”。
二、问题解决方案分析
1、 分页时会出现重复数据
问题出现的原因是排序所依据的键值变换频繁,导致翻页语句在执行时数据已经发生了变化。我们需要找到一个可以用于排序的值,一个即能根据热点趋势及时变化,又相对固定不变的值。
开始时,觉得挺矛盾的,解决了一个问题却加剧了另一个问题,直到发觉这个排序值可以和解决最热榜单霸屏问题使用一个值,思路就开始打开了。
2、 最热榜单被霸屏
尝试了把问题的被查看时间参与到排序规则中,使得排序可以每个小时刷新1次。上线后,榜单是真的变了起来,最新被查看的问题能够浮上来,但是当热门问题也被查看后依然会霸屏。
这个改良版的排序方法,其实就是文末参考资料中描述的Delicious算法的思路,这是最直接、最简单的算法,按照单位时间内用户的投票数进行排名,得票最多的项目,自然就排在第一位。
这个算法的优点是简单、容易部署、内容更新快;缺点是,一方面,排名变化不够平滑,前一个小时还排名靠前的内容,往往第二个小时就一落千丈,另一方面,缺乏自动淘汰旧内容的机制,某些热门内容可能会长期占据排行榜前列。
最热榜单开始变化的几天中,运营从数据上查看,问题的整体访问情况要好于调整之前,虽然由于使用姿势不正确带来了数据重复的bug,但证明最热榜单的排序动起来是很有意义的。在咨询公司大数据的专业人士“溥神”后,给我们推荐了业内解决这种问题的通用算法之一“牛顿冷却定律”,开始更科学的解决这个问题。
定律的解读
伟大的物理学家牛顿,早在17世纪就提出了温度冷却的数学公式,被后人称作”牛顿冷却定律“(Newton’s Law of Cooling)。

牛顿冷却定律有广泛的用途。例如,人死亡以后温度调节功能随即消失,因此借助于由正常体温(约为37摄氏度)与环境温度的比较,利用这个定律,就可以判定死亡的时间。
举个实际计算的例子。某冬晨,警察局接到报案,在街头发现一具尸体。在6点30分的时候,测量其体温为18摄氏度,到 7点30分已下降到16摄氏度。假设室外气温维持在约10摄氏度不变,而且设人体正常体温是37摄氏度,问这个人是什么时候死的?

【来自得到电子书《不可思议的自然对数》】
如果我们把”热文排名”想象成一个”自然冷却”的过程,那么如下的场景是成立的:
- 当前温度。任一时刻,网站中所有的文章,都有一个”当前温度”,温度最高的文章就排在第一位。
- 冷却。随着时间流逝,所有文章的温度都逐渐”冷却”。
- 加温。如果一个用户对某篇文章投了赞成票,该文章的温度就上升一度。
上面的这种场景,概括起来就是新的内容总是会替代老的内容,而它又恰好类似于物理学当中的“牛顿冷却定律”。本质上它描述了高于周围温度的物体会向外散热,并逐渐降温的过程,同时单位时间内散热与周围温差会成正比关系。这样假设的意义,在于我们可以照搬物理学的冷却定律,使用现成的公式,建立”温度”与”时间”之间的函数关系,从而构建一个”指数式衰减”(Exponential decay)的过程。
结论
物体的冷却速度,与其当前温度与室温之间的温差成正比,我们可以参考牛顿冷却定律构建问答最热排名的算法。新加一个用于排序的值,俗气点就叫热度值(hot value),这个值周期性的更新规则。
三、影响因素与实践过程
由于问答已经有了”最新上架“的榜单,我们的”最热“榜单不需要重点关注新上架内容的曝光,所以也就不需要完全采用定义一个初始温度来逐步降温的模式。
问答的最热榜单,希望能根据用户最近的实际查看量(例如前一天的查看量),同时结合上架时间的因素,来决定今天的热度排序。于是我们重点关注决定降温趋势的时间因子,用户行为的加温值,由此来计算热度值,公式入下:
热度值 = 加温值 * 时间因子
1、时间因子
无论对于用户还是平台,显然是不希望一直是同样的内容霸占了排行榜或者列表的最前面位置的,而是希望不断被更新的内容所替代。站在用户的角度上,一方面当然是希望对于一些比较热门的问题能够及时看到,但另外一方面还是希望能不断看到新的东西。
对于任一内容,在某一定时间段之后,排列顺序能够发生周期性的变化,内容的热度需要随时时间的推移而慢慢衰减,这个周期就是降温周期,在周期内最好能呈现出下面这样的一种趋势:
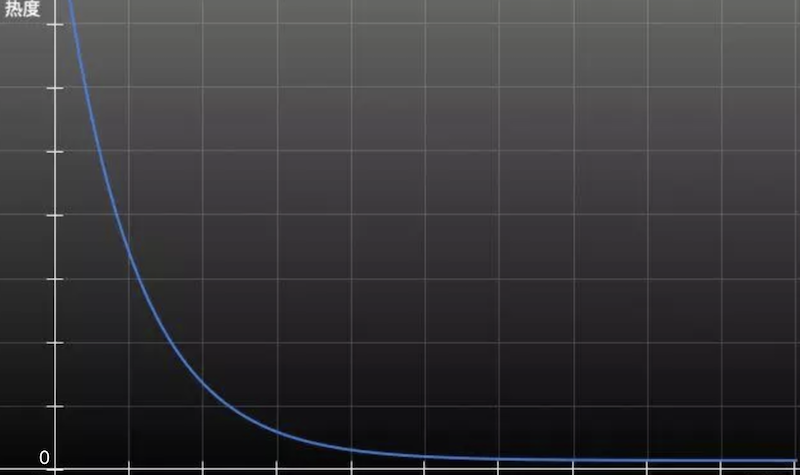
降温周期,可以理解为刷新文章热度的时间间隔。具体的间隔多少则需要根据平台的内容量来确定,如果内容较多,希望尽快呈现新的内容给用户,便可以把时间间隔设置的比较短;如果内容较少,则可以把间隔时间设置的比较长。截至到这篇文档初次编写的时候(2020-02-12 18:43),我们问答的数量是298,所以应该把间隔时间设置的长些,例如30天。
实践:经过观察和数据调试,把问答热点问题的降温趋势定义在了30天,即我们新上线的问题从100°降到0°的时间为30天左右,在这期间所有上架的问题都有机会被加温升上来。当天上架的问题,只要被浏览,那么就可以优先级最高的机会被排到前面。
2、用户行为的加温值
如果只是有上面提到的热度因素,那么可能会导致的问题是,有很多相近或者同一时间段上架的问题,热度值随着时间的推移降低的速度几乎是一致的,这就还会导致内容的排名也基本上是一致的。为了解决这样的问题,还可以在除了初始热度以外,引入问题被发布后用户对其产生的一些行为,常见的行为可以包括浏览、评价、收藏、分享、点赞等。
目前我们在问题列表里只展示了查看量,为了更容易被理解,我们先只把查看量当做加温值。
实践:在问题信息的扩展表中增加一列来记录昨日被查看量(yesterday_count ),每天更新这个值,这样根据准实时总查看量和昨日总查看量的差值,就能计算出当日的查看量,作为计算热度值的重要参数。
3、热度值的计算
关键点:热度因子和昨日被查看量,直接决定了一个问题的热度值,影响“最热”排序。
热度值的更新:目前定在了每天凌晨的2点钟,直接用sql来计算更新。
版本1 、参考牛顿冷却定律
热度因子取一个和时间反比例缩小的值。这个版本,采用了如下的计算方式,问题会在35天左右衰减。
热度因子factor = (1+ROUND(1 / (DATEDIFF(当前时间,首次被浏览的时间) + 1),2) * 100)
加温值 = 昨日浏览量 = 总浏览量 - 昨日浏览量
热度值 HotValue = 加温值 * factor
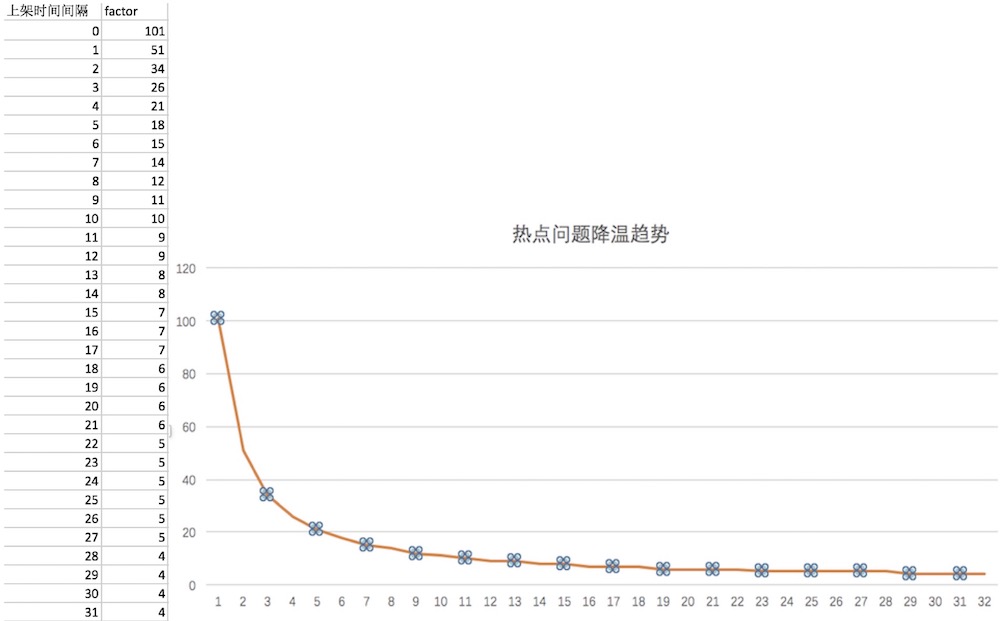
实际效果: 如下是初次写稿时(2020-02-12 19:33)的一个线上问题top 10,从结果可以看到,前面的那几个霸屏问题已经被排到了下面,新上架的问题按规则排到了前面。
这个版本解决的问题
1、解决了分页排序数据重复的问题。由于HotValue只在固定的时间段更新,我们按照HotValue排序相当于按照了一个固定的值,所以出现重复数据的几率大大降低,在2020-02-10日下午上线后,再没有发现。
2、问题的热度排序更加科学,增加了老问题的曝光几率,看到了热度降温的效果,对于学习牛顿冷却定律更有兴趣了。
这个版本存在的问题
1、前期降温过快
问题上架的第一天是100°,第二天就直接降到了50°,如果问题在第一天的加温情况并不好(查看量较低),那么就会被排到后面。
2、冷却期较长
35天左右才会降到0°,而产品经理希望以后能调整到15天左右试试,而这个版本的算法比较费劲,调整多次都达不到期望的效果。
版本1的实验过程:
- 2月8日 确定方案,添加基础支撑的字段
- 2月9日 记录昨日查看量,上线计算热度值算法
- 2月10日 更新了线上的排序策略
版本2、使用牛顿冷却定律的公式改进
1、改进热度因子
经过版本1的数据和经验积累,最终求出了几个适合问答现状的值,即降到冰点天数和冷却系数的定义。
热度因子fac = ROUND(exp(-冷却系数* DATEDIFF(当前时间,首次被浏览的时间) * 24 ),2) * 100
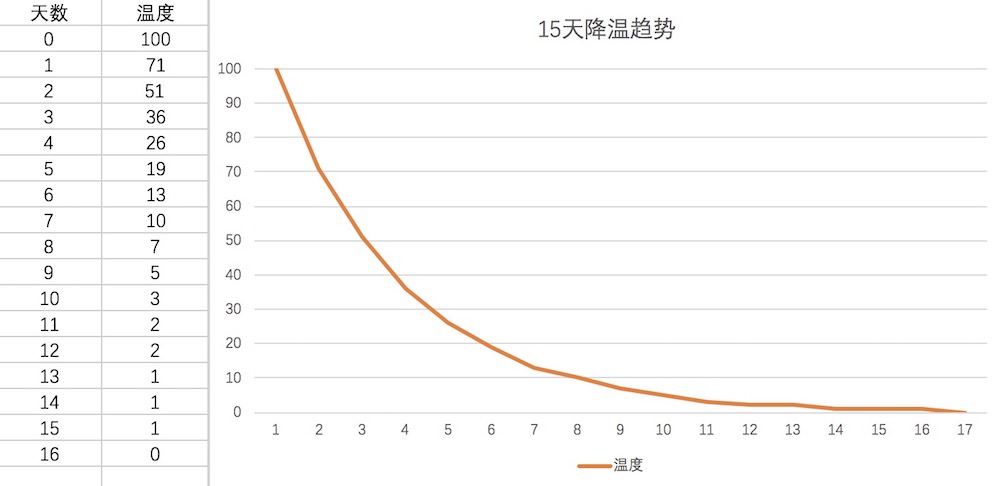
30天的降温趋势图如下,降温趋势将更加平滑了。
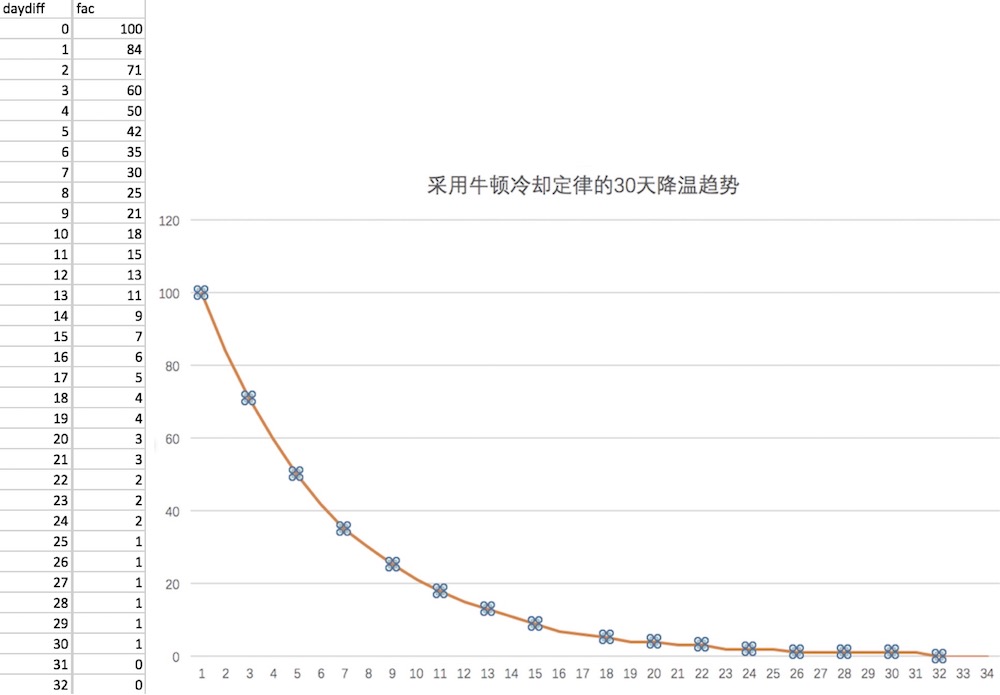
提前计算了几个适用的冷却参数,当问题达到一定数量的时候,可以加快降温的速度,这点是版本1所不具备的。
| 冷却天数 | 冷却系数 |
|---|---|
| 30天 | 0.0072 |
| 15天 | 0.014 |
| 10天 | 0.022 |
2、改进加温因子
可以把留言数、收藏数等值加进来,实现类似如下的加温值:
加温值 = 浏览量50% + 留言量20%+收藏量*30% ……
版本2的实施:
- 2月21日,修改热度因子的计算规则为版本2
- 等正式发布的问题数量接近1000时,可以考虑把冷却天数缩短为15天
最后,我们看一张图,2020-03-08女神节问题最热榜单的排序情况。在第20条以后,我们看到上线超过30天热度因子为0的几个问题,由于昨日访问量增加到一定程度,也有机会上浮到前面了。

思考与结语
1、定律使用要结合实际的场景
牛顿冷却定律是伟大的,但使用时要结合实际的场景,不能生搬硬套。
在算法刚上线时,我还是按照Delicious算法的惯性思路,觉得榜单要动起来就该让榜单在一天中刷新多次,结果由于新上线内容的热度因子值较大,导致最新和最热榜单的排序在第1页几乎完全一样,这样的话最热榜单意义就被打了折扣。
资料中的对牛顿冷却定律的使用,都是定义一个初始热度值再去逐渐降温,而我们的产品中由于有了最新的榜单,也采用这种方式的话,也会导致榜单数据重合。
2、最热排序未来的优化方向
在内容的总量达到一定程度之前,可以由服务端对所有用户统一规则排序展示,当到达一定规模后,毫无疑问,个性化的推荐算法就一定是更好的了。
在内容的数量接近1000个时,会把降温的速度加快,15天后就降低到冰点。
3、牛顿冷却定律适用的场景
通过阅读资料和实践,单就排序而言,个人觉得牛顿冷却定律适用于投票策略以正方向为主的场景,例如浏览、留言、收藏这些都是加温行为,即使各个行为的权重不同,对于排序的影响都是正向的,唯一的负方向值就是时间。
如果打分排序的场景还需要同时考虑正方向和负方向的投票行为,牛顿冷却定律就不太适用了。比如同一个内容,有的读者觉得有帮助会顶一顶增加正值,有的读者觉得没意义会踩一踩增加负值,平台希望内容列表的排序规则,即考虑时间因素又结合用户投票还要客观公正,算法可就没有那么简单了!
最后列举列举了一些相关的文章和参考资料,感兴趣的读者们可以继续延伸阅读。
- https://baike.baidu.com/item/长尾效应/6352848?fr=aladdin 长尾效应
- http://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_newton_s_law_of_cooling.html 基于用户投票的排名算法(四):牛顿冷却定律
- http://www.woshipm.com/pd/2970177.html 信息流优化:牛顿冷却定律的应用
- https://www.ruanyifeng.com/blog/2012/02/ranking_algorithm_hacker_news.html 基于用户投票的排名算法(一):Delicious和Hacker News
- https://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_reddit.html 基于用户投票的排名算法(二):Reddit
- https://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_stack_overflow.html 基于用户投票的排名算法(三):Stack Overflow
- https://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_newton_s_law_of_cooling.html 基于用户投票的排名算法(四):牛顿冷却定律
- https://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_wilson_score_interval.html 基于用户投票的排名算法(五):威尔逊区间
- https://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_bayesian_average.html 基于用户投票的排名算法(六):贝叶斯平均
- 得到电子书《不可思议的自然对数》