0x0 pre
弹性伸缩, 是云计算中的一种常用方法,通过该方法,服务器池中的计算资源量(通常根据有效的服务器数量来衡量)会根据服务器池中的负载进行动态伸缩。
本文旨在为想在 kubernetes 中使用弹性伸缩功能
的读者解释相关概念,并制定一条较为清晰的路线图。
0x1 autoscaling
在了解 k8s 弹性伸缩这个课题之前,我们先从更宏观的角度,了解一下弹性伸缩相关概念。
目的
我们做工程都是结果导向的,就是说,我们做弹性伸缩,不是因为它看上去很酷,不是为了做弹性伸缩而做。
而是从公司的实际问题出发,为了解决什么问题,以及投入产出比是否合理,才决定是否要做弹性伸缩,以及怎么做。
一般来讲,弹性伸缩主要用来解决两个问题:
- 应对突发流量
- 节省资源
应对突发流量。这点很好理解,当系统由于外界因素(比如 XXX 突然结婚了, XXX 突然离婚了等突发的热门话题),
导致系统负载激增,原有的配置已无法满足需求,需要增加系统配置。这种增加可能是自动的,可能是需要手工调整的,
甚至是需要去购买机器,重启服务等对服务比较不友好的行为。具体进行何种操作,需要以及目前公司的弹性伸缩级别来制定
相应的计划。关于弹性伸缩的级别,我们将在稍后说明。
节省资源。绝大多数情况下,我们不可能让我们的工作负载跑满服务器(即便能跑满,为了服务稳定性,我们也不大敢这么做)。
在不损失服务稳定性的大前提下,尽可能地提高资源利用率,一直是各个弹性伸缩方案不懈的目标。减少单个服务资源占用,
通过合理调度资源减少服务器数量,及时增减服务数量等手段,都能直接或间接的达到节省资源的目的。
针对以上两种目的,我们可能设计出完全不同的弹性伸缩方案。
例如,如果我们的需求是 在流量激增时能够在数分钟内为指定服务扩容,保证服务稳定可用,那么我们可能仅仅需要
把服务迁移到容器环境中,并配置一个延迟较低的监控报警系统,在出问题时能够及时通知到运维人员,然后手动为服务扩容即可;
如果服务器成本在公司所有成本中已经占了很大的比重,要在不影响业务的情况下尽可能地减少服务器开支,秒级伸缩,则我们需要
从公司后端服务各个方面好好设计一番了。
场景
节点和服务
节点是承载工作负载的单元,是集群中提供容器运行环境的一台机器(物理机或虚拟机)。
服务是具体的工作负载,具体在 kubernetes 中,就是 pod 以及 pod 所包含的容器。
kubernetes 上的弹性伸缩会在节点和服务两个粒度进行。
两个粒度之间会相互影响。例如,应对突发流量时,如果触发了服务粒度的扩容操作,就会占用部分节点资源,
如果碰巧扩容到一半时,集群所有资源都被用完了,那么此时只有节点也能进行自动扩容才能完成服务的扩容,
否则会导致服务由于没有找到足够的资源而扩容失败。当然,现实情况中,我们一般不会等到集群资源完全用完
时才去触发节点扩容。一般会在资源超过某个特定阈值(90-95%)时,就会触发扩容。
同样,在使用缩容来节省资源时,只有将负载低的服务缩容后,才能空闲出一批利用率较低的节点,此时节点弹性伸缩器检测到
某些节点利用率低,关闭这些节点,或是从云厂商取消续订这些节点,才能达到节省资源的最终目的。
垂直伸缩与水平伸缩
垂直(Vertical)伸缩:调整节点或服务的资源配额。
水平(Horizontal)伸缩: 调整节点或服务的数量。
弹性伸缩的级别。
借鉴业界对自动驾驶的分级规则,现定义服务的弹性伸缩级别如下:
| 级别 | 说明 | 扩展 | 收缩 | 业务是否感知 | 操作时间 |
|---|---|---|---|---|---|
| 0 | 系统不支持伸缩 | - | - | - | - |
| 1 | 运维手动添加机器 | 人工 | 人工 | 是 | x 小时 |
| 2 | 管理系统中修改配置 | 人工 | 人工 | 否 | x 分钟 |
| 3 | 自动扩容 | 自动 | 人工 | 否 | 扩展 x 秒,收缩 x 分钟 |
| 4 | 自动伸缩 | 自动 | 自动 | 否 | x 秒 |
| 5 | 按计划伸缩 | 自动 | 自动 | 否 | x 秒 |
| 6 | 基于预测的伸缩 | 自动 | 自动 | 否 | x 秒 |
level 0: 系统还处在比较原始的阶段,服务不支持任何形式的扩容缩容。
level 1:系统直接跑在自己维护的虚拟机或物理机上,能够通过人工增加减少机器数量来实现扩缩容。
此种方式的通常方案是在服务上层搭建一个负载均衡,然后在增加、减少机器时使负载均衡感知。
这种方式扩缩容的时间通常较长,几分钟到几小时不等。
level 2:
- 服务已经容器化
- 有一套标准的容器调度管理平台(mesos/kubernetes)
- 有一套完整的监控数据(prometheus/zabbix/open-falcon/ELK)
由于容器的启动速度比虚拟机和物理机要快很多,所以容器化后,可以将扩容速度提高很多倍,能够达到秒级至分钟级。
level 3:
由于 level 2 中我们已经有个各个维度的监控数据,在此基础之上,可以做一些自动化策略来减少人工操作的时间,
能够将扩容速度稳定在秒级。
level 4:
在弹性伸缩的级别中,自动缩容的等级(4)要比自动扩容(3)高一级,主要从两个方面考虑:
- 从公司发展角度来看,肯定是先跑起来 –> 抗住大流量 –> 精细化控制成本。
如果温饱问题都还没有解决, 公司生死存亡的问题都还没解决, 就去考虑节约成本,显然是没有抓对发展的大方向。 - 从实现的技术难度来讲,缩容要考虑的细节要多一些。比如扩容时由于都是添加资源和服务,较容易做到业务无感知。
但是在缩容时,如果想做到业务无感知,可能需要结合网关、负载均衡、部署策略、服务优雅关闭、服务发现、
容器生性周期管理等多方面的知识才能实现。
此外,在制定弹性伸缩策略时,业界通常会采用 激进的扩容,谨慎的缩容 的大方针来最大限度地保障服务的稳定性。
level 5:
level 3 和 level 4 虽说已经实现了秒级的弹性伸缩,但是他们都是被动式的,换句话说,只能在事情发生后,
再进行扩缩容。这样做可能会导致出现少量的请求超时或请求出错。一种更优雅的方案是在出现问题前,预先准备好充足的资源,
避免问题的发生,前置性地进行伸缩。
level 5 周期性的弹性伸缩是指基于对历史数据和公司、服务业务的资源用量波峰波谷的周期性规律的总结,定时对服务和集群
规模进行扩缩容。
例如如果公司主要业务是一款公交出行类软件,那么很显然每天的早晚上班期间是公司业务的高峰,且流量是闲时流量的数倍。该公司
可以指定一个定时伸缩策略,每天早晨 5 点将集群规模扩大 x 倍,xx 业务规模扩大 y 倍,11 点再缩容至原规模,下午 4 点再进行扩容,
以此类推。level 5 的弹性伸缩的实现,依赖于 level 3 和 level 4 对基础设施和中间件的优化与改造,只有在能保证扩缩容的过程中
不会对业务产生影响,才可以频繁地进行扩缩容。
level 6:
level 5 的周期性伸缩用一种简单地预测性的方式很好的解决了公司常规业务的资源使用率的问题。但由于仅仅采集了时间维度对系统资源使用
情况影响的数据,其调整方式较为单一,无法应对突发情况。
通常情况下,在系统出现高流量,高负载前,都会有一些前置性信号。这些信号包括但不限于以下方面:
- 基于以往压测数据和以往运营活动数据对即将开展的营销活动的流量的预测
- 利用社会工程学手段对社会上即将发生的热点事件和正在发生的热点事件的走向的预测
- 利用机器学习对系统响应时间、流量走势、系统负载走势等多维度海量监控数据的分析对即将到来的高流量和高负载的预测(例如 netflx 的预测分析引擎Scryer)
技术手段能够解决许多问题,但是并不能解决所有问题。在解决系统性问题时,尤其是较复杂的系统问题时,我们不能把思维完全限制在技术领域,
同时结合多种手段,可以使许多看似无法用技术手段解决的问题迎刃而解。
当然,随着机器学习技术的兴起,一些以往无法用传统方式解决的技术问题,也变得可解。只不过需要专业人士投入较多的人力物力,在使用
这种方式时,要在充分考虑投入产出比后,再做决定。
Netflix发现,对于部分基础架构和特定的工作负载,其预测分析引擎 Scryer 比传统的被动自动缩放方法提供了更好的结果。它特别适合以下场景:
- 在不久的将来识别需求的巨大峰值,并提前一点准备好产能
- 处理大规模中断,例如整个可用区和区域的故障
- 处理可变的流量模式,根据一天中不同时间的典型需求水平和变化率,在横向扩展或纵向扩展速率上提供更大的灵活性
任何系统和工程都不是一蹴而就的,只有当基础设施达到一定完善程度后,再逐级实现弹性伸缩,才是一个比较可行的路线。
本文假定目前系统已经达到了2 级的弹性伸缩。以下主要讲述在此基础上,实现更高级的弹性伸缩的相关知识点。
0x2 autoscaling in kubernetes
弹性伸缩这种功能,不是很多系统都已经实现了,我们直接用就行了吗,为什么还需要个指南呢。
因为。。。。我们先来看看都有哪些相关知识点吧。。。

弹性伸缩涉及到各种软硬件,各色调度平台,策略和系统,其本身就是一个较复杂的课题。此外,kubernetes 不单单是一个容器调度平台,而是一个活跃,庞大的生态系统。
kubernetes 弹性伸缩这个课题涉及了诸多知识点,主要如下:
- 水平(Horizontal)伸缩
- 垂直(Vertical)伸缩
- 定时(Scheduled)伸缩
- 预测(Predictive)性伸缩
- 服务画像
- node
- service
- CA
- cloudprovider
- VPA
- HPA
- HPA controller
- metric
- metric server
- heapster
- metric state
- prometheus
- CRD
- custom metric api
- prometheus adapter
- cronhpa controller
- cloud controller manager在刚开始调研这个课题的时候,一上来看到这么多名词和术语,肯定会一脸懵逼的。终于,
在知识的海洋中遨游了好一阵后,终于了摸索出一条路,爬上岸来。
接下来我们开始逐步详细讲解并绘制路线图。
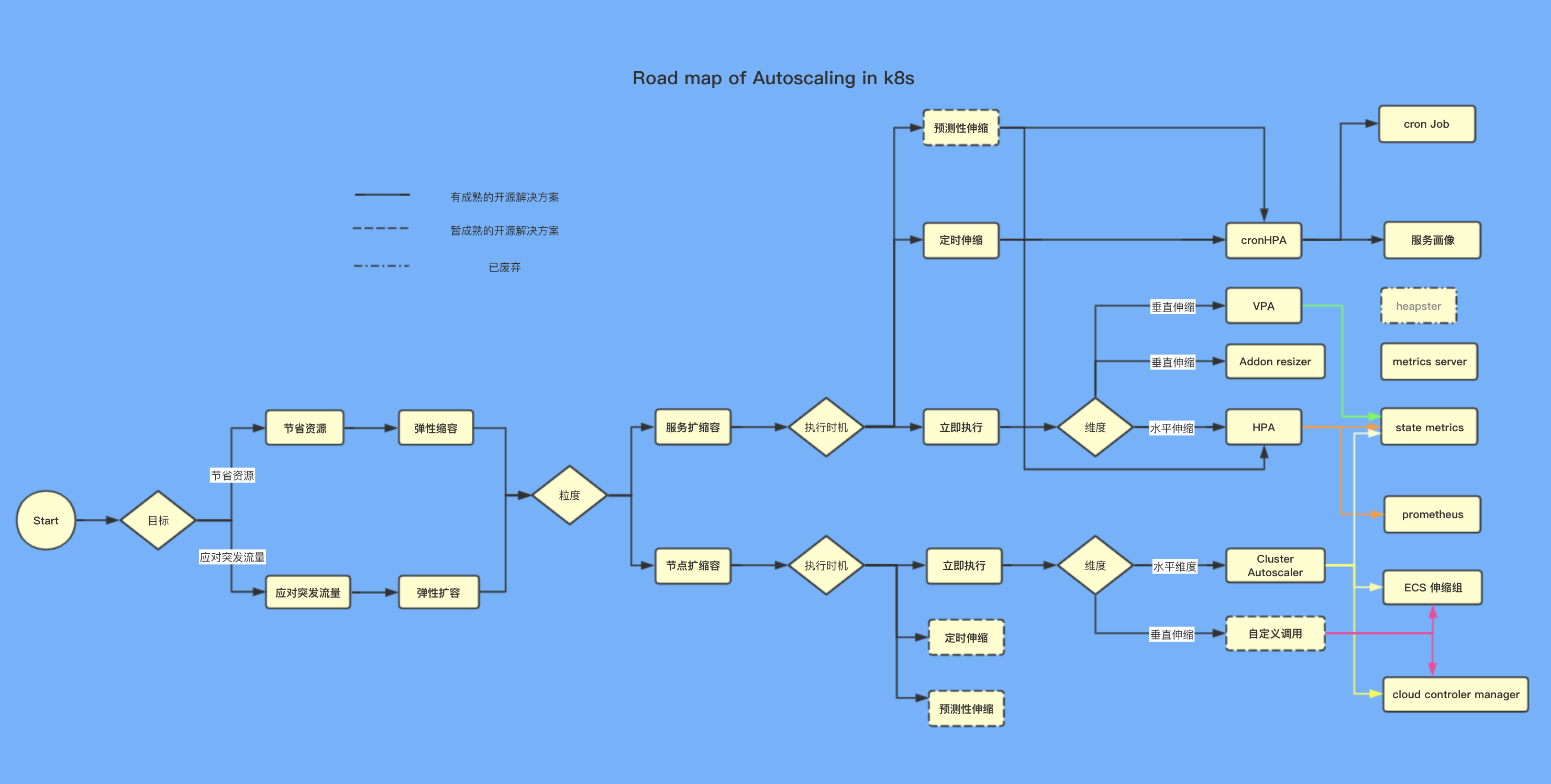
service autoscaling
首先,按照伸缩粒度,分为服务伸缩和节点伸缩。我们先来看服务伸缩。
k8s 默认提供了多个服务粒度的弹性伸缩组件。主要有 VPA, addon resizer 和 HPA。
此外,各大云厂商也积极贡献提供了多种伸缩组件,例如阿里云提供的 cronHPA。
以下我们分别详细说明。
在服务粒度的伸缩中,依据执行触发时机不同,可分为立即执行,定时执行和预测性执行。
先来看立即执行。
立即执行又细分为垂直伸缩和水平伸缩。
垂直伸缩
k8s 中的垂直伸缩一般是指调整 Pod 的内存和 CPU 配额(resource limit 和 request)。
k8s 官方 autoscaler 包中有两个类型的垂直伸缩组件:
VPA(vertical pod autoscaler) 和 addon resizer。
addon resizer可以根据集群节点数量来动态地调整某个其他 deployment 中的 pod 的配额。
addon resizer 周期性地查看集群节点数量,然后计算出监控的 pod 需要分配的内存和 CPU,如果 pod 的实际 pod 配额
和所需配额超过某个阈值,则会修改 deployment 并触发生成新的 pod。addon resizer 的这种特性决定了它用来伸缩与集群
规模密切相关的服务。一般, addon resizer 用来伸缩部署在集群内的 heapster, metrics-server, kube-state-metrics
等监控组件。
VPA的应用范围要广一些。设置 VPA 后,它能够自动为 pod 设定 request 和 limit 配额值,然后动态地将 pod 调度
到合适的节点上去。
VPA 在 k8s 中定义类型为 VerticalPodAutoscaler 的 CRD,
为每个需要开启垂直弹性伸缩功能的 deployment 创建一个 custom resource,然后 VPA 会定期查看对应 pod 的资源使用情况,结合历史数据,
自动调整 pod 的配额。
VPA controller 由三部分组成。
- Recommender:它监视当前和过去的资源消耗,并基于此提供容器的cpu和内存请求的推荐值。
- Updater:它检查哪个托管的pod设置了正确的资源,如果没有,则杀死它们,以便它们的控制器可以用更新后的请求重新创建它们。
- Admission Plugin:它在新pod上设置正确的资源请求(由于Updater的活动,它们的控制器只是创建或重新创建了这些请求)。
使用 VPA 监控 deployment 时,它并不会去改变 deployment 的配置,而是使用 admission plugin 以类似 pre hook 的方式
在创建 pod 时动态为其配置配额值。
使用 VPA 之前需要注意以下问题:
- VPA 默认会从 metrics server 中采集历史数据,因此使用 VPA 之前,需要配置好 metrics server。VPA 也支持从 prometheus 中
采集历史数据,不过需要额外的配置。关于 metrics server、state metrics、prometheus 等监控服务的异同,我们将在 数据监控一节中
详细介绍 - VPA 是在伸缩调整过程中,是通过重启 pod 来使调整生效的,因此已经公司基础架构不同,可能会引起服务闪断,需要具体分析服务是否可接受
- 使用 VPA 扩容有上限,具体受 pod 所在宿主机影响。为 pod 分配的资源无法超过宿主机的大小。如果 recommender 计算出的 pod 所需资源
超过节点可用资源,将导致 pod 一直 pending。这点可与通过与 cluster autoscaler 共同使用来部分解决。 - VPA 目前不应与基于内存和 CPU 监控的水平Pod自动调度器(HPA)一起使用,否则可能产生预期外的行为。
水平伸缩
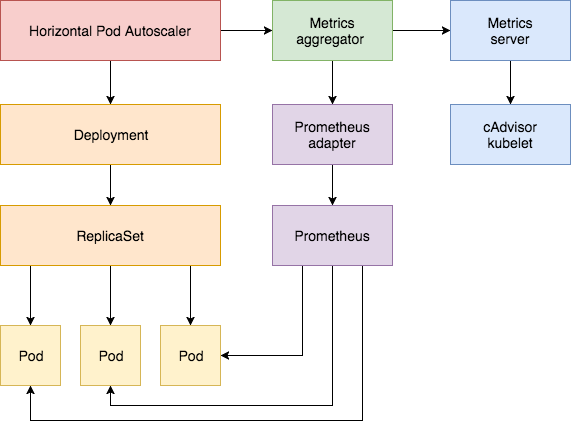
Horizontal Pod Autoscaler 是 k8s 内置的水平伸缩控制器。 它根据观察到的CPU使用率(或使用自定义指标支持,基于某些其他应用程序提供的指标)
自动缩放 replication 控制器,deployment,副本集或状态集中的 pod 数量。 需要注意的是,水平窗格自动缩放不适用于无法缩放的对象,
例如DaemonSets。
HPA 实现为Kubernetes API资源和控制器。资源决定控制器的行为。控制器定期(默认为 15 秒)调整复制控制器或部署中的副本数量,
以使所观察到的平均CPU利用率与用户指定的目标相匹配。
与 VPA 仅支持从 metrics server 中采集 CPU 和内存数据不同的是,HPA 支持多种数据维度和数据采集方式:
- 从 heapster 中采集 CPU 和内存数据(自 kubernetes 1.11 起废除)
- 遵循特定格式记录在 annotation 中的应用自定义 metrics(自 kubernetes 1.6 起废除)
- 使用 metrics API 采集 metric server 中的数据
- 通过 custom metrics adapter 将 prometheus 等第三方中的数据采集提供给 custom metrics API 使用。
和 VPA 一样,使用 HPA 一般需要先搭建 metrics server,具体方法可参考 kubernetes 官方指南。
在新版本(kubernetes 1.6 以后)的 metrics API 中,引入聚合层(aggregation layer),为应用查询 metrics server
内部的数据和第三方数据提供了一致的抽象。第三方监控数据只需自己实现相应的 adapter,并在 metrcis API 中为其
监控的 metric 注册相应的 custom metrics API 即可。
下图展示了使用 HPA 根据 metrics server 和 prometheus 中的数据进行弹性伸缩的过程。
定时伸缩
kubernetes 官方并没有提供定时伸缩相关的组件,但是其原理并不难,只需按照设定的时间调用 kubernetes 的 API 即可。
kubernetes-cronhpa-controller 是阿里云工程师基于 go-cron
开源的定时伸缩组件。
预测性伸缩
目前暂无成熟的技术方案。
node autoscaling
垂直伸缩
与 kubernetes 本身关系不大,其功能主要取决于云厂商。例如,厂商是否支持主机的升降配,以及升降配过程中是否
需要重启主机等。如果需要重启主机,那么在进行伸缩之前,我们需要先把节点上的 pod 驱逐到其他主机。
但是如果我们是由于机器资源不够用而扩容的话,这样会加剧资源不够用的情况,造成更大的 pending 状态的 pod。
因此,如果如果云厂商不支持不重启就能扩容的话,我们不建议采用这种方式进行节点扩容。
水平伸缩
CA(Cluster Autoscaler) 是 kubernetes 官方的节点水平伸缩组件。
它可以在下列条件之一为真时自动调整Kubernetes集群的大小:
- 集群中有 pod 由于资源不足而一直 pending
- 集群中有些节点在很长一段时间内没有得到充分利用,且其上的 pod 可以被调度到其他节点上。
cluster autoscaler 虽然是 kubernetes 官方标准,但是由于其去云厂商依赖较深,因此具体使用方法,功能以及限制以
云厂商具体实现为准。目前支持以下云厂商: Google Cloud Platform, AWS, AliCloud, Azure, BaiduCloud。
以 AliCloud 为例,默认单个用户按量付费实例的配额是30台,单个VPC的路由表限额是50条;且每个可用区的同一类型的实例
库存容量波动很大,如果短时间内大量购买同一区同一配置的实例,很容易出现库存不足导致扩容失败。
建议在伸缩组中配置多种同规格的实例类型,提高节点伸缩成功率。
实际使用中,一般为 node 建立多个 node group,专门配置几个 group 来启用弹性伸缩应对突发流量进行扩缩容。
主要的 group 并不进行扩缩容,来避免扩缩容导致对大范围的服务的影响。
此外,节点水平伸缩能否成功实施,与调度策略密切相关。kubernetes 在为 pod 选择可分配节点时,
是采用 LeastRequestedPriority 策略,简单来说就是就是尽可能把资源打散,把 pod 分配到资源利用率低的节点。
这样会倒是有一批利用率较低,但未到缩容阈值的节点,因此会导致无法成功缩容,资源利用率低。因此实际使用时,需要
调整 kubernetes 调度策略,来达到最优的结果。
定时伸缩
目前暂无成熟的技术方案。
数据监控
heapster
heapster 是一个数据收集器,从每个 node 上采集数据并进行汇总,然后转存到第三方工具中,
它本身并不生成监控数据,也不负责存储。
目前 heapster 已经被逐渐废弃(从 kubernetes 1.11 开始),不再维护和推荐使用。
heapster 曾负责以下功能:
- 监控节点、pod 的 cpu 内存基础数据。这部分数据采自每个节点的 cadvisor(新版本的 kubernetes 已集成到 kubelet)。
- 通用的数据项目监控。
- kubernetes 事件信号转发。 heapster 调用 api-server 并将集群的 event 转发处理。
目前这三个功能可依次由 metrics server、pormetheus operator、eventrouter 等独立的组件替换。
metrics server
metrics server 是 heapster 的继承者,kubernetes 1.8 开始,集群内监控数据可以通过 metrics API
从监控数据聚合器 metrics server 中获取。
Metrics API相比于之前的监控采集方式(hepaster)是一种新的思路,官方希望核心指标的监控应该是稳定的,版本可控的,
可以直接被用户访问(kubectl top),也可以由组件通过 API 调用。由于监控数据量巨大,不适宜像其他资源一样存到 etcd 中,
因此 Metrics server 将数据存在内存中,只提供实时数据的查询,不提供历史数据查询功能。
除了可以通过 metrics API 查询内部监控数据外,metrics server 提供了灵感的扩展方式。
系统可以为自定义监控数据实现对应的 adapter, 用户就可以以 custom metrics API 的方式查询数据,保持与查询原生数据一致的体验。
通常, metrics server 的数据可作为各个维度弹性伸缩的数据指标。
state metrics
kube-state-metrics 侦听 Kubernetes API服务器并生成关于对象状态的指标。它并不关注Kubernetes组件的健康状况,而是关注内部各种对象
(如 deployment、node 和 pod)的健康状况。
我们可以直接访问 Kube-state-metrics 的 /metrics HTTP 接口来查看监控数据。 这些数据用来提供给 prometheus 获取其它一些第三方程序
抓取使用。
关于 state metrics 和 metrics server 的差异:
metrics server 仅采集 kubernetes 中的 CPU、内存等核心指标,它周期性地调用所有节点的 kubelet
提供的 summary API。这些数据是按 pod、node 维度聚合的,存储在内存中,并且以 metrics API
的格式提供。它仅存储最新数据,并且不负责将这些数据导出提供给第三方使用。
kube state metrics 主要关注于从 deployment, replica set, stateful set 等 kubernetes
对象生成新的监控数据,将原始数据重新聚合、呈现。它在内存中存储整个 kubernetes 集群的状态快照,并在此之上持续生成新的监控数据。同样,
它也负责将这些数据导出提供给第三方使用。prometheus
用于存储、聚合、查询监控数据的时序型数据库。
0x3 方案对比
下面对上述方案从以下几方面做统一比对:
- 稳定性:在伸缩时尽可能保证服务稳定性是大前提。
- 接入成本:实现弹性伸缩的一个重要目的就是节省成本,如果接入成本太高就得不偿失了。
- 灵活性:在落地到具体公司时,每个公司的开发语言、框架、服务类型多种多样,不同服务对弹性伸缩的要求不尽相同。
- 数据源丰富性:每个成熟的 IT 公司都有一套自己的监控报警体系,收集了诸多维度的数据,如果能更好的利用这些数据,将能够实现更精准的弹性伸缩。
- 混合云支持:随着公司规模扩大,云服务费用日益增高,越来越多的公司开始组建多机房,多云服务供应商组建的混合云。
| 方案名 | 功能简述 | 优点 | 缺点 | 混合云支持 |
|---|---|---|---|---|
| Horizontal Pod Autoscaler | 根据服务负载调整服务实例数 | 稳定性:扩容是通过增加实例数来实现,对原有容器无影响,因此稳定性较好。 接入成本:k8s 原生支持,只需配置 k8s 资源即可实现基本功能。 数据源丰富性:有一定的灵活性,可以直接采集 kubelet 数据,也可基于 prometheus 采集的自定义数据。 | 灵活性:判定机制较简单,一次命中即触发伸缩,无法配置次数阈值,无法解决毛刺问题;无法自定义触发动作(如通知等) | 否 |
| Vertical Pod Autoscaler | 根据服务负载调整 pod 的资源分配数 | 接入成本:k8s 原生支持,只需配置 k8s 资源即可实现基本功能。 数据源丰富性:有一定的灵活性,可以直接采集 kubelet 数据,也可基于 prometheus 采集的自定义数据。 | 稳定性:伸缩时会重新发版,触发过程可能会加剧请求超时现象,可能引发宕机时间。 灵活性:判定机制较简单,一次命中即触发伸缩,无法配置次数阈值,无法解决毛刺问题;无法自定义触发动作(如通知等)。 | 否 |
| Cluster Autoscaler | 根据 pod 和节点状态增减集群节点数 | 接入成本:成熟开源方案,且官方适配了阿里云,配置即可。 稳定性:方案较成熟。 | 数据源:不支持自定义。 灵活性:较不灵活。 | 否 |
| kubernetes-cronhpa-controller | 阿里云基于 go-cron 开源的定时伸缩服务组件。 | 稳定性:目前该功能已上线阿里云 k8s 服务,较稳定。 接入成本:较低,配置即可。 | 灵活性:无法支持伸缩前校验,伸缩后通知等自定义操作。 | 否 |
0x4 其他
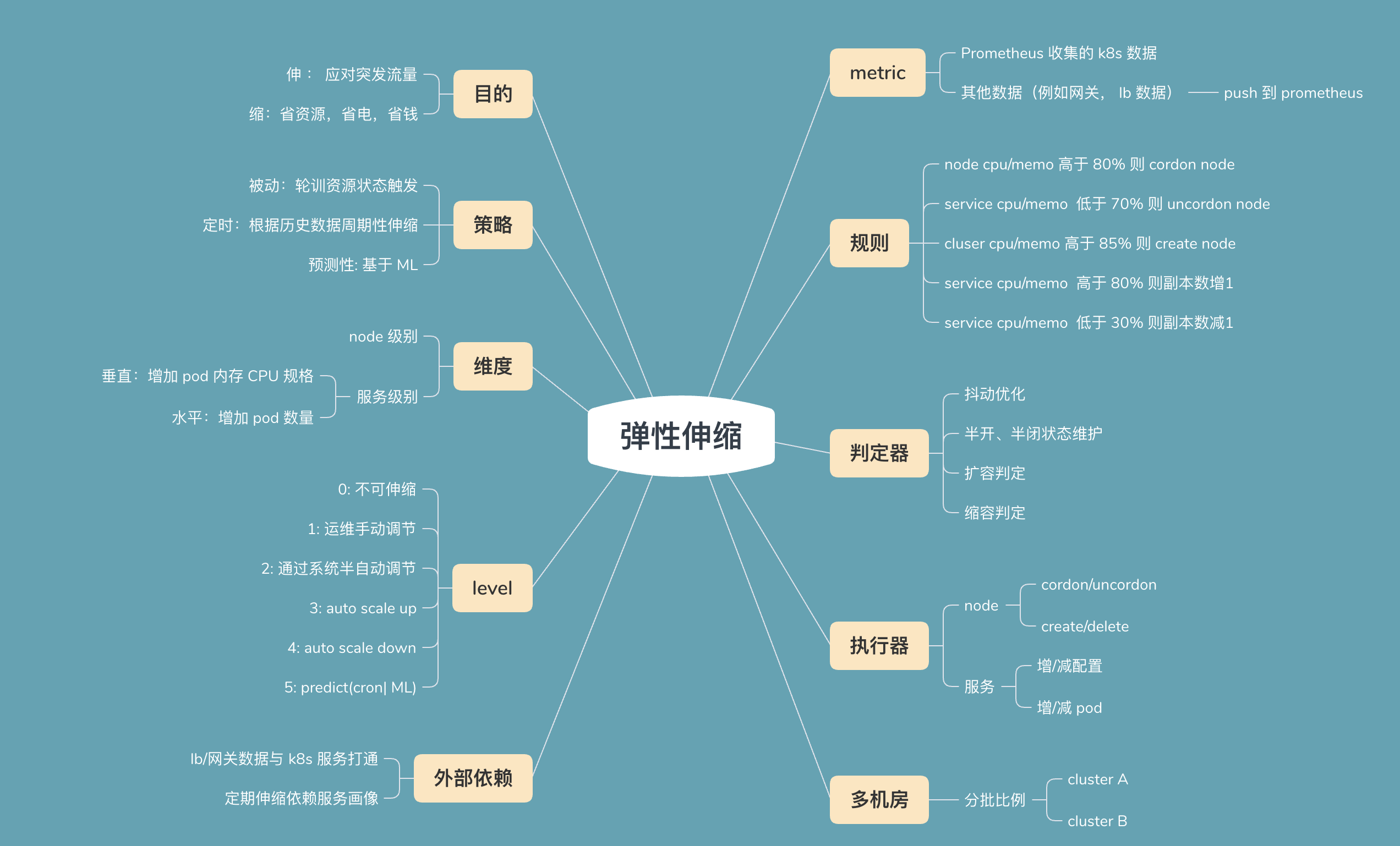
最后分享一张我们分析弹性伸缩时用到的思维导图:
好了,弹性伸缩相关路径我们都已经基本熟悉了,我们又可以踏上征程,
去探索维斯特洛大陆(kubernetes)其他的版块了。