引言
并发编程是一个经典的话题,由于摩尔定律已经改变,芯片性能虽然仍在不断提高,但相比加快CPU的速度,计算机正在向多核化方向发展。虚拟化的赋能,让多核服务器的弹性创建和扩容都更加便捷。为了尽可能的提高程序的性能,硬件,操作系统,程序编译器进行一系列的设计和优化,但是同时,带来了影响并发安全的3类问题:
- cpu增加了缓存,以均衡与内存的速度差异,但是带来了可见性问题
- 操作系统增加了线程,行程,分时复用cpu以增加cpu利用率,但是带来的线程切换的原子性问题
- 编译程序优化指令次序,但是带来了有序性问题
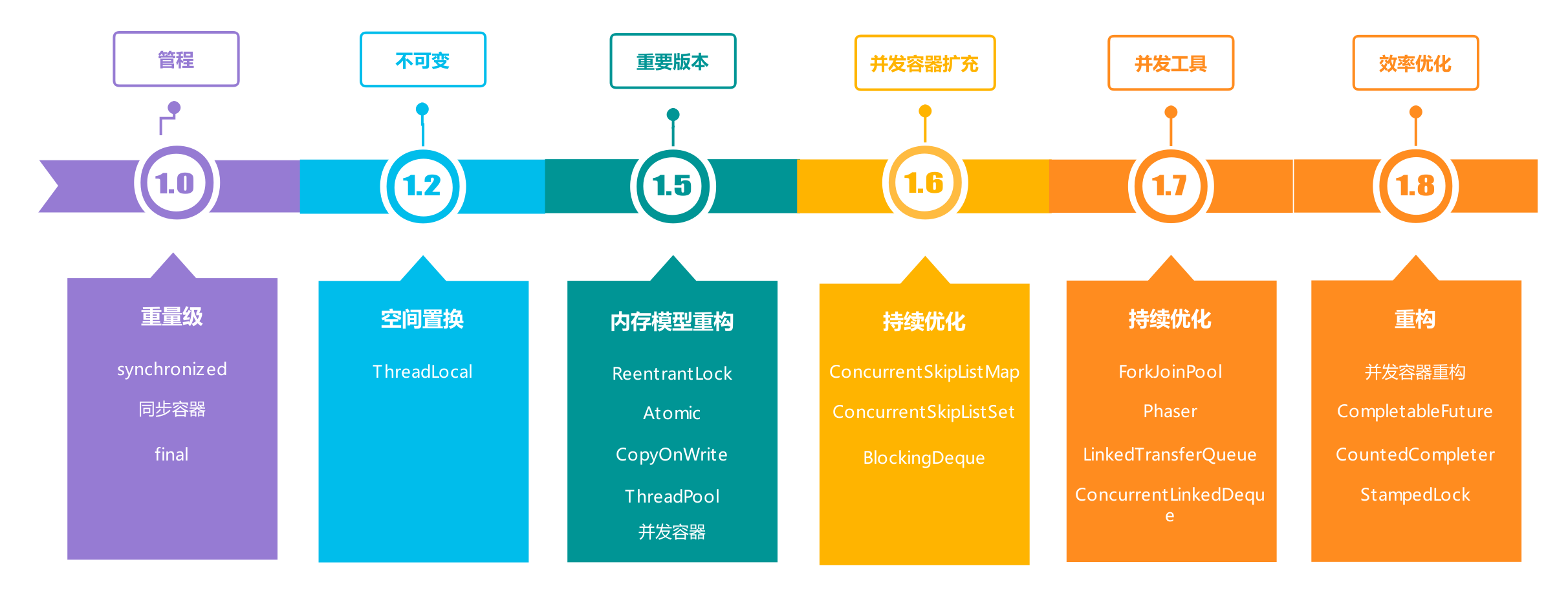
Java作为互联网后端最主流的高级语言,以及大数据工程的事实标准语言,从诞生初始并发编程就是其重要特性之一。Java提供了许多基本的并发功能来辅助多线程应用程序的开发。从1.5之前基于管程模型的同步锁,到1.5内存模型重构后广泛使用的CAS+AQS的乐观模型,随着版本的演进,并发编程的操作难度越来越低,但是另一方面,相对底层的并发功能与上层的应用程序的并发语义之间并不存在一种简单而直观的映射关系。
因此,即使面对众多并发工具,开发人员可能也陷入着无法选取合理武器的困局,为了能正确且高效的使用这些功能,对Java提供的并发工具有一个系统的大局观并了解其原理是Java开发人员必须关注的重点。本文将通过几个最具有代表性的问题的剖析,展现Java并发设计的核心关键点,为最佳实践打好理论基础。
synchronized 和 Lock 可以互相替代吗?
synchronized是Java1.0即加入的并发解决方案,其原理为只支持一个条件变量的简化后的MESA模型。而Lock是Java1.5加入的基于完整MESA模型的Api原语。解答是否可以互相替代的问题,可以先从区别比较入手:
| synchronized | Lock
— | — | —
形态 | Jvm层面的关键字 | Java语言层面的Api
管程模型 | 只支持一个条件变量的简化后的MESA模型 | 支持多个条件变量的完整MESA模型
锁的获取 | 进入同步代码块即开始竞争锁,未获得锁的线程会一直等待 | 可以通过API实现多种多样的的竞争
锁的释放 | 1.持有锁的线程发生异常,Jvm强制线程释放锁
2.拥有锁的线程执行完同步代码块,自动释放 | 基于Api的手动释放
锁类型 | 可重入,不可中断,不可公平 | 可重入,可中断,可公平
锁状态 |无法判断 | 通过Api判断
取舍 | 1.6优化后性能是Lock的两倍 |基于管程语义的Api功能更强大
通过表格中的对比非常明显的得出,Lock可以在大部分情况下替换synchronize,但是反过来不然。对于两者的使用,有以下最佳实践方案:
- 优先使用synchronized,当不满足并发需求时使用Lock,如多个条件变量,希望竞争公平等
- 使用Lock时注意两个范式:try-finally 和 乐观自旋
下面是两种工具实现的阻塞队列,其间区别非常明显:
synchronized
1 | //很标准的模式,没有扩展点 |
2 | public class BlockQueue { |
3 | private final int maxSize; |
4 | private LinkedList<Integer> values; |
5 | |
6 | BlockQueue(int size) { |
7 | maxSize = size; |
8 | values = new LinkedList<>(); |
9 | } |
10 | |
11 | public void put(int value) throws InterruptedException{ |
12 | //可以锁values,也可以锁BlockQueue.class |
13 | synchronized (values) { |
14 | while (values.size() == maxSize) { |
15 | try { |
16 | values.wait(); |
17 | } catch (InterruptedException ex) { |
18 | ex.printStackTrace(); |
19 | } |
20 | } |
21 | values.add(value); |
22 | values.notifyAll(); |
23 | } |
24 | } |
25 | |
26 | public int take() throws InterruptedException{ |
27 | synchronized (values) { |
28 | while (values.size() == 0) { |
29 | try { |
30 | values.wait(); |
31 | } catch (InterruptedException e) { |
32 | e.printStackTrace(); |
33 | } |
34 | } |
35 | values.notifyAll(); |
36 | return values.removeFirst(); |
37 | } |
38 | } |
39 | } |
Lock
1 | |
2 | public class BlockQueue { |
3 | private final int maxSize; |
4 | private ReentrantLock lock; |
5 | private Condition notFull; |
6 | private Condition notEmpty; |
7 | private LinkedList<Integer> values; |
8 | |
9 | BlockQueue(int size) { |
10 | //公平锁,讲究先来后到 |
11 | lock = new ReentrantLock(true); |
12 | //两个条件变量 |
13 | notFull = lock.newCondition(); |
14 | notEmpty = lock.newCondition(); |
15 | maxSize = size; |
16 | values = new LinkedList<>(); |
17 | } |
18 | |
19 | public void put(int value) { |
20 | //尝试1分钟 |
21 | lock.tryLock(1, TimeUnit.MINUTES); |
22 | //try-finally范式 |
23 | try { |
24 | //while范式,可以判断锁的状态 |
25 | while (values.size() == maxSize && lock.isLocked()) { |
26 | //阻塞线程至相应条件变量的等待队列 |
27 | notFull.await(); |
28 | } |
29 | values.add(value); |
30 | //唤醒相应条件变量的等待队列中的线程 |
31 | notEmpty.signalAll(); |
32 | } catch (Exception e) { |
33 | } finally { |
34 | lock.unlock(); |
35 | } |
36 | } |
37 | |
38 | public int take() { |
39 | int value; |
40 | //获取可以被中断的锁,当被中断时,需要处理InterruptedException |
41 | lock.lockInterruptibly(); |
42 | try { |
43 | while (values.size() == 0 && lock.isLocked()) { |
44 | notEmpty.await(); |
45 | } |
46 | notFull.signalAll(); |
47 | } catch (InterruptedException e) { |
48 | if (Thread.currentThread().isInterrupted() { |
49 | System.out.println(Thread.currentThread().getName() + " interrupted."); |
50 | } |
51 | } finally { |
52 | value = values.poll(); |
53 | lock.unlock(); |
54 | } |
55 | return value; |
56 | } |
57 | } |
当然,在Java中是不需要自己手写阻塞队列的,Java1.8 并发包中提供了7种实现,满足各类场景的需求
如何按需定制一个线程池
在并发处理的场景下,程序可能要频繁的创建线程工作,完毕后销毁。虽然Java中创建线程就像new 一个对象一样简单,销毁也是Jvm的GC自动搞定的。但实际上创建线程是非常复杂的。创建一个普通对象,仅仅是在Jvm的堆内存中划分一块内存而已。而创建一个线程,却需要调用操作系统的Api分配一系列资源,这个成本和对象无法相提并论的。
程序中应该避免频繁创建和销毁如此重量级的线程对象,标准的解决方案就是池技术,在Java中,ThreadPoolExecutor就是线程池工具。
不同于标准的池模型,ThreadPoolExecutor没有acquire方法获得资源,没有release方法释放资源,其通过7个构造参数构建了生产者-消费者的模式。
线程池的内部核心原理是内部通过阻塞队列来缓存任务,调用execute方法的线程为生产者,内部的一组工作线程为消费者,获得Runnable任务并执行。
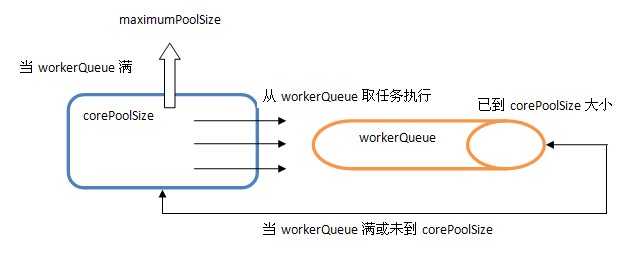
正确使用线程池就是正确配置其构造参数,有以下最佳实践或注意事项:
- 不要使用工厂类Executors创建线程池,由于其内部默认使用无界的LinkedBlockingQueue,高负载情况下无界队列很可能导致OOM,同时这也表明,使用阻塞队列必须设定容量。
- 基于1,由于队列有界,如果任务重要程度较高的情况下必须关注队列已满的情况的下线程池拒绝策略的设置,默认的抛出拒绝异常策略可能导致问题,此时可以自定义策略做补偿或者降级操作。
- 必须给线程池中的线程指定有辨识度的名称用于问题出现时是JVM栈信息排查。可以通过参数threadFactory包装设定策略
- 队列容量的设定,有一个标准公式:CPU核数 * [1 + (IO耗时/CPU耗时) ] ,但是考虑落地成本过高,可采用大部分场景适用的公式:2 * CPU核数+1,程序运行后通过监控慢慢优化至最优
- 设定不同的阻塞队列将得到支撑不同场景的线程池,在日常大部分场景下,使用指定容量的LinkedBlockingQueue和ArrayBlockingQueue可以满足需求,一个就基本的选择原则是:采用读写锁分离的LinkedBlockingQueue,但是由于内部数据结构的原因,LinkedBlockingQueue会产生更多的内存消耗,如果对GC敏感即采用单锁的ArrayBlockingQueue
ThreadPoolExecutor
1 | |
2 | public class ThreadPool { |
3 | |
4 | // Atomic* 是Java并发工具包中的原子类,核心原理是CAS |
5 | final AtomicInteger poolNumber = new AtomicInteger(1); |
6 | |
7 | //4c情况下的设定 |
8 | ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(9, 12, |
9 | 10L, TimeUnit.SECONDS, |
10 | new LinkedBlockingQueue<>(20), |
11 | new ThreadFactory() { |
12 | |
13 | @Override |
14 | public Thread newThread(Runnable r) { |
15 | return new Thread(r, "THREAD-POOL-EXAMPLE-" + poolNumber.getAndIncrement()); |
16 | } |
17 | }, |
18 | new RejectedExecutionHandler() { |
19 | @Override |
20 | public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { |
21 | //todo 启动补偿或者降级操作,比如将任务放到消息队列或者数据库,启动另外一个补偿线程进行任务 |
22 | } |
23 | } |
24 | ); |
25 | } |
优先使用并发容器,但是并发容器那么多,何时该使用何种?
在1.5之前,Java的同步容器是保证线程安全的数据结构集合,由于采用了synchronized来保证互斥性能很差。在1.5版本,Doug Lea大神提供了性能高度优化的并发容器包。并发容器的类型非常丰富,所以何时该使用何种?如同《Effective Java》中提到:”标准类库有那么多优点,为何程序员没有使用呢,答案可能是程序员并不知道这些类库的存在。”
所以,用好并发容器就需要开发者对并发包的成员有一个全面的了解,从分类来看:
- List:CopyOnWriteArrayList 是空间换时间的思路,写时将共享变量新复制出来一份,读可以完全无锁。适用场景:写操作少,数据量不大,可容忍短暂的读写不一致。
- Map:ConcurrentHashMap,ConcurrentSkipListMap。ConcurrentHashMap的底层还是HashMap,而ConcurrentSkipListMap是1.6后加入的,其底层是跳表,跳表本身是一种比较复杂的数据类型,对于插入,删除,查询操作的平均时间复杂度都是O(log n),相比HashMap底层的红黑树是一种非常稳定的数据结构,如果对程序稳定性有要求可以选择ConcurrentSkipListMap
- Set:CopyOnWriteArraySet,ConcurrentSkipLisSet。原理同上
- BlockingQueue & BlockingDeque:单端队列和双端队列,并发包中最复杂的组件集合,需要关注的:
- 单端队列Queue是指只能队尾入队,队首出队,双端队列Deque是指队首队尾都可入队出队。
- 需要特别关注,生产环境中一定要使用有界队列,无界队列可能会产生OOM。
- BlockingQueue的应用场景最为广泛,更与线程池紧密联系在一起,对于阻塞队列不同的配置将得到完全不同的线程池,比如代码示例,Spring使用ScheduledThreadPoolExecutor来实现任务调度器@Scheduled,ScheduledThreadPoolExecutor内部使用的就是支持延时的阻塞队列BlockingQueue
ScheduledThreadPoolExecutor关键代码
1 | |
2 | public static ScheduledExecutorService newSingleThreadScheduledExecutor() { |
3 | return new DelegatedScheduledExecutorService |
4 | (new ScheduledThreadPoolExecutor(1)); |
5 | } |
6 | |
7 | |
8 | public ScheduledThreadPoolExecutor(int corePoolSize) { |
9 | super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, |
10 | new DelayedWorkQueue()); |
11 | } |
12 | |
13 | //其内部原理是在入队和出队时对队列中的元素按照堆二叉树排序,保证延时时间少的任务首先出队 |
14 | |
15 | static class DelayedWorkQueue extends AbstractQueue<Runnable> implements BlockingQueue<Runnable> { |
16 | |
17 | ****** |
18 | |
19 | //在offer方法被调用时将入堆的元素排序至正确的位置 |
20 | private void siftUp(int k, RunnableScheduledFuture<?> key) |
21 | // 当k==0时跳出循环,表名已经遍历到堆二叉树的根节点了 |
22 | while (k > 0) { |
23 | int parent = (k - 1) >>> 1; |
24 | RunnableScheduledFuture<?> e = queue[parent]; |
25 | if (key.compareTo(e) >= 0) |
26 | break; |
27 | queue[k] = e; |
28 | setIndex(e, k); |
29 | k = parent; |
30 | } |
31 | queue[k] = key; |
32 | setIndex(key, k); |
33 | } |
34 | |
35 | //在移除元素时排序 |
36 | private void siftDown(int k, RunnableScheduledFuture<?> key) { |
37 | int half = size >>> 1; |
38 | while (k < half) { |
39 | int child = (k << 1) + 1; |
40 | RunnableScheduledFuture<?> c = queue[child]; |
41 | int right = child + 1; |
42 | if (right < size && c.compareTo(queue[right]) > 0) |
43 | c = queue[child = right]; |
44 | if (key.compareTo(c) <= 0) |
45 | break; |
46 | queue[k] = c; |
47 | setIndex(c, k); |
48 | k = child; |
49 | } |
50 | queue[k] = key; |
51 | setIndex(key, k); |
52 | } |
53 | |
54 | ****** |
实战:实现一个限流器
在互联网应用中,限流是一个非常高频的词。由于有限资源下的Api接口可支撑的QPS也是有限的,为了保护服务不被超越能力的尖峰流量,或DDOS攻击打挂,应用限流算法来对Api进行主动防护。
- Token bucket 令牌桶
- Leaky bucket 漏桶
- Fixed window counter 固定窗口计数
- Sliding window log 滑动窗口日志
- Sliding window counter 滑动窗口计数
其中令牌桶算法由于能够在限流的基础上,处理一定量的突发请求,成为最主流的限流算法。
令牌桶算法,核心可以简单总结为:有一个桶存放令牌,每一个请求会消耗一个令牌,另一边以固定速率向桶中放令牌,当令牌消耗速率大于放入的速率时,Api不提供服务,此时可以执行相应的措施,比如等待,拒绝,降级等。
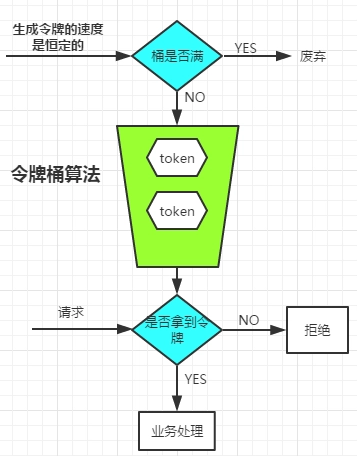
可以看到,存放令牌的桶会出现并发操作,由一个生产者,和一组消费者产生竞争。貌似我们通过类似线程池的生产者-消费者模型就像能解决问题了:一个生产者线程定时向阻塞队列添加令牌,试图通过限流器的线程从阻塞队列中获取到令牌就可以执行任务。但是在实际场景中,需要限流的场景一般都是高并发的,如果系统的压力已经接近极限了,生产者定时器的精度误差会非常大,会很大程度的影响限流器的稳定性。
而在单机JVM中最广泛使用的限流器,是Google的Guava包中的限流器RateLimiter,其巧妙的增强了令牌桶算法,提供包括两种限流策略:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp),一个标准使用方法如下:
RateLimiter 示例
1 | public class RateLimiterSimple { |
2 | |
3 | public static void main(String[] args) { |
4 | |
5 | //限定QPS = 5 |
6 | RateLimiter rateLimiter = RateLimiter.create(5.0); |
7 | |
8 | ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, |
9 | 0L, TimeUnit.MILLISECONDS, |
10 | new LinkedBlockingQueue<>(1), |
11 | r -> new Thread(r, "RATE-LIMITER-EXAMPLE-THREAD"), |
12 | (r, executor) -> { |
13 | //todo 启动补偿或者降级操作,比如将任务放到消息队列或者数据库,启动另外一个补偿线程进行任务 |
14 | } |
15 | ); |
16 | |
17 | long start = System.currentTimeMillis(); |
18 | for (int i = 0; i < 10; i++) { |
19 | long s = System.currentTimeMillis(); |
20 | //获得令牌前阻塞 |
21 | rateLimiter.acquire(); |
22 | threadPoolExecutor.execute(() -> { |
23 | long now = System.currentTimeMillis(); |
24 | System.out.println((now - s)); |
25 | }); |
26 | } |
27 | long end = System.currentTimeMillis(); |
28 | System.out.println("cost time " + (end - start)); |
29 | |
30 | } |
31 | } |
32 | |
33 | //运行结果,每秒通过5个请求 |
34 | 3 |
35 | 150 |
36 | 204 |
37 | 201 |
38 | 203 |
39 | 196 |
40 | 200 |
41 | 203 |
42 | 201 |
43 | 200 |
44 | cost time1757 |
RateLimiter的关键巧妙设计是:记录并动态计算下一个令牌发放的时间,每一次acquire操作都会触发Ratelimiter的时间槽变化,而令牌桶在这里仅仅是一个虚拟的概念了。
RateLimiter 核心代码
1 | |
2 | //核心方法:若当前时间晚于nextFreeTicketMicros,则计算该段时间内可以生成多少令牌,将生成的令牌加入令牌桶中并更新数据。 |
3 | void resync(long nowMicros) { |
4 | if (nowMicros > nextFreeTicketMicros) { |
5 | double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros(); |
6 | storedPermits = min(maxPermits, storedPermits + newPermits); |
7 | nextFreeTicketMicros = nowMicros; |
8 | } |
9 | } |
RateLimiter的设计非常巧妙,也很抽象,是否有其他简单的解决思路呢?
那就是Java并发包中提供的线程协作工具包。其一系列的协作工具可以解决并发下线程之间的协作依赖关系,最有代表性的包括:
- CountDownLatch 闭锁,基于计数器的主线程通知器
- CyclicBarrier 栅栏锁,基于屏障的多线程协调
- Semaphore 信号量,基于管程实现的信号量,应用于有限资源的抢占
- Phaser 阶段器,多个线程分阶段共同完成任务
- ForkJoinPool,JVM单机内的 Map/Reduce 模型
其中Semaphore模型,常用于管理有限资源资源的分配,在限流器需求场景下,令牌桶中的令牌就可以认为是这些有限资源,而信号量就是令牌桶。
基于Semaphore模型实现的简单限流器
1 | |
2 | public class SemaphoreLimter { |
3 | |
4 | private Semaphore semaphore; |
5 | |
6 | //size即为固定的QPS限额 |
7 | SemaphoreLimter(int size) { |
8 | semaphore = new Semaphore(size); |
9 | } |
10 | |
11 | void acquire(Runnable r) { |
12 | //依然是try/finally 范式 |
13 | try { |
14 | semaphore.acquire(); |
15 | r.run(); |
16 | } catch (InterruptedException e) { |
17 | e.printStackTrace(); |
18 | } finally { |
19 | semaphore.release(); |
20 | } |
21 | } |
22 | } |
参考资料
- 《Java Concurrency in Practice》
- 《Effective Java》
- Java并发编程实战 - 极客时间