你还在为可爱的小朋友向基于Yarn进行资源调度的大数据集群提交巨牛无比的笛卡尔积任务而苦恼吗?
你还在为不知道如何让可爱的小朋友乖乖地在正确的资源调度队列里排队而惆怅吗?
本文将为你简要分享我罗是如何从粗放式资源调度的蛮荒阶段,过渡到现如今在Hive+Sentry+Hue的使用环境下,通过Cloudera Manager提供的公平调度器、动态资源池和Linux cgroups实现队列资源隔离、队列资源可伸缩、队列访问控制的精确治理阶段。
背景
目的
- 协调计算资源,实现队列资源隔离、队列资源可伸缩:保障azkaban调度用户绝对有资源可用的同时,满足其他用户即席查询的需求
- 结合Sentry和Linux cgroups,实现队列的访问控制
基本需求
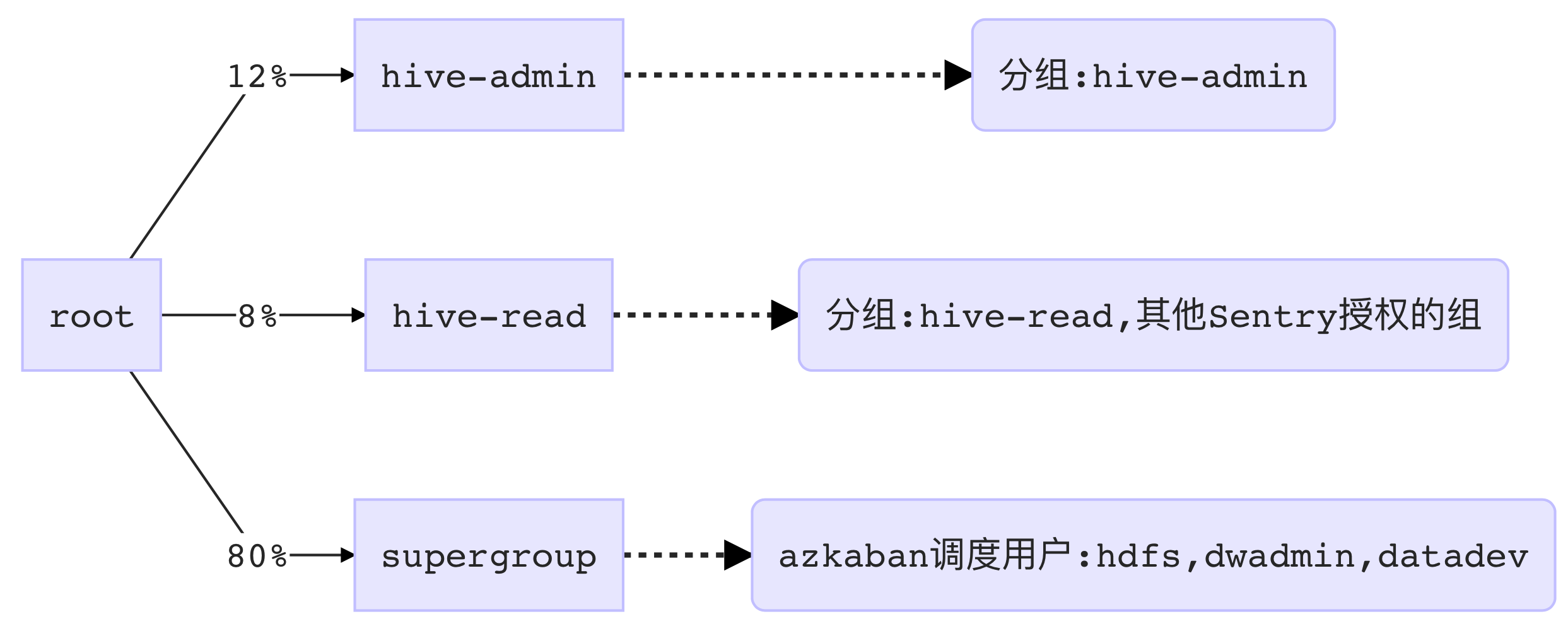
用户组及权值分配说明
| 分组 | 说明 | 权值 | 成员 |
|---|---|---|---|
| supergroup | azkaban调度用户; 通过Hive Gateway提交任务 |
80 | hdfs, dwadmin, datadev |
| hive-admin | Hive+Sentry 认证用户, 分组与Sentry一致; 一般通过Hue等工具提交任务 |
12 | 我罗大数据中心成员 |
| hive-read | 一般通过Hue等工具提交任务 | 8 | 我罗大数据中心之外的成员 |
| Sentry未授权用户 | 被Sentry拦截 | — | UNDEFINED |
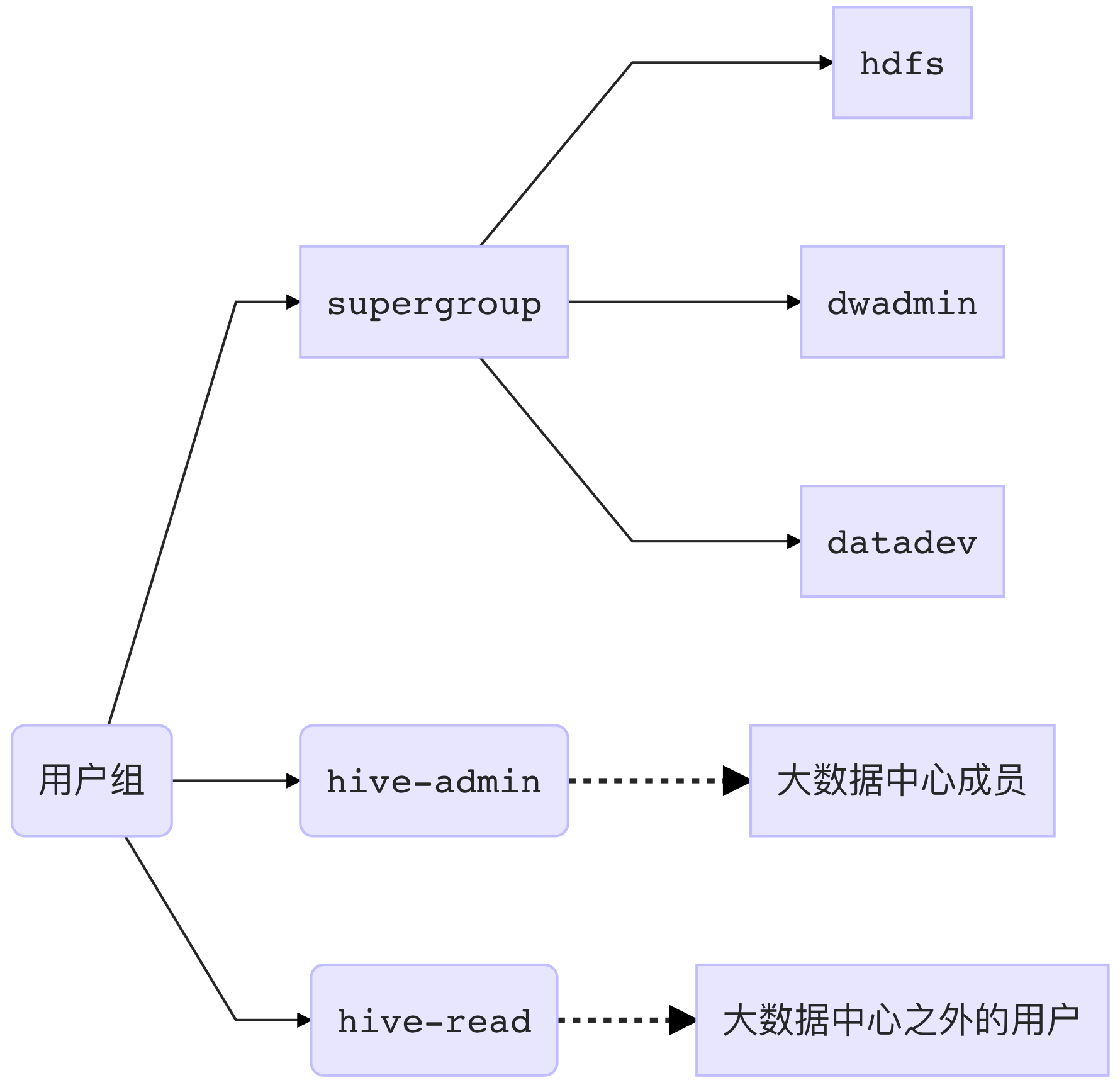
队列(资源池)访问控制
| 队列(资源池) | 可提交组 | 管理组 |
|---|---|---|
| supergroup | supergroup | supergroup |
| hive-admin | hive-admin | hive-admin,supergroup |
| hive-read | * | hive-admin,supergroup |
队列配置
由需求可以梳理出Yarn资源调度队列配置:
公平调度器
Cloudera Manager 推荐使用该调度器,且对该调度器的支持力度最大,可以配合动态资源池和Sentry灵活地按照队列放置规则,将特定用户提交的任务放置到特定的队列中,并通过ACL严格限制队列的访问。
配置详解
Overview
为了便于管理用户提交的任务,因此将用户分组,提交任务时按分组提交到对应的队列中。具体规则如下:
yarn-site.xml
在 Cloudera Manager -> 集群 -> Yarn -> 配置 中直接搜索配置项
1 | # 禁止未声明的资源池 |
2 | yarn.scheduler.fair.allow-undeclared-pools = false |
3 | # 禁止公平调度器抢占 |
4 | yarn.scheduler.fair.preemption = false |
5 | # 禁止以用户名作为默认队列 |
6 | yarn.scheduler.fair.user-as-default-queue = false |
7 | # 禁用,以使队列内部分配资源的时候,采用轮询方式公平地为每个应用分配资源。若设为true,则可以设置权重,权重越大,分配的资源越多 |
8 | yarn.scheduler.fair.sizebasedweight = false |
9 | # 开启Yarn的ACL |
10 | yarn.acl.enable=true |
资源池
路径:集群 -> 动态资源池 -> Yarn -> 资源池
Overview
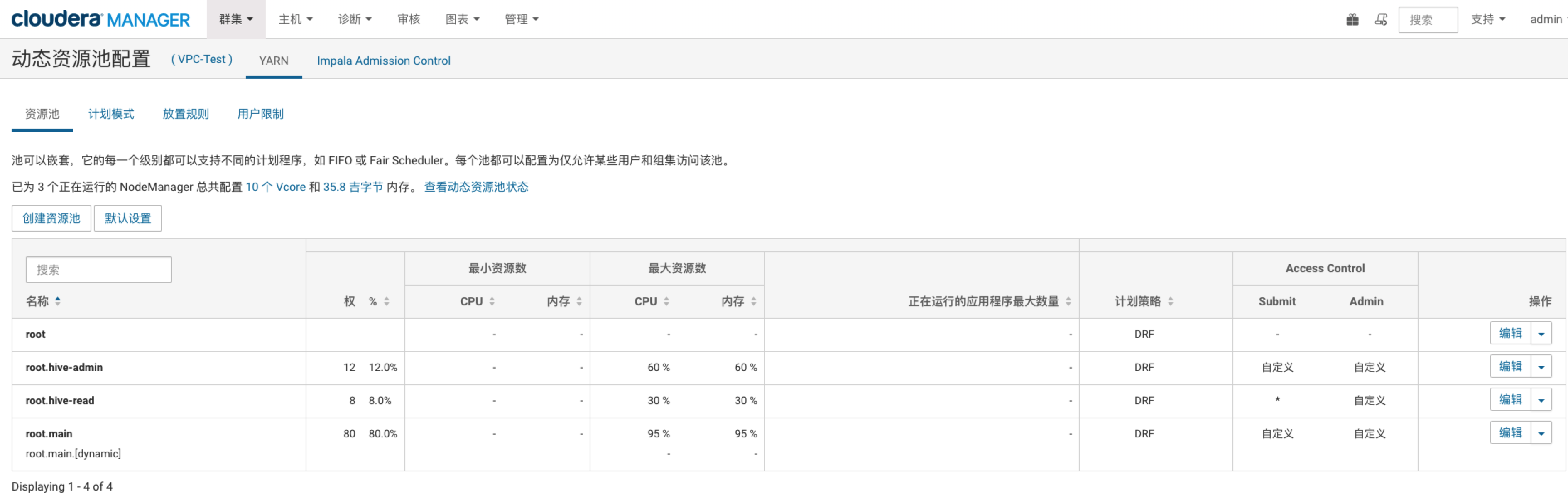
配置说明
| 配置 | 描述 | 默认值 | 设置 |
|---|---|---|---|
| 权 | 队列之间按权值分配资源 | — | 如上图 |
| 最大/小资源数 | 该配置会覆盖权,即该配置优先级高于按权分配的最大值限制; 这里只加入最大资源数限制,保证某个队列不会占用过多的资源。 |
— | 如上图 |
| 计划策略 | CM推荐使用DRF,按照CPU和内存分配资源 | DRF | ALL: DRF |
| Application Master 最大份额 |
限制可用于运行 ApplicationMaster 的资源池公平份额的比例。 例如,如果设为 1.0,叶池中的 ApplicationMaster 最多可使用 100% 的内存和 CPU 公平份额; 如果值为 -1.0,将禁用 ApplicationMaster 份额的监控。 |
0.5 | ALL:-1.0 |
ACL
root.supergroup:
- 提交访问控制 组:supergroup,用户:datadev,dwadmin,hdfs
- 管理访问控制 组:supergroup,用户:datadev,dwadmin,hdfs
root.hive-admin:
- 提交访问控制 组:hive-admin
- 管理访问控制 组:hive-admin
root.hive-read:
- 提交访问控制 用户:* (允许任何用户向该池提交)
- 管理访问控制 组:hive-admin
放置规则
路径:集群 -> 动态资源池 -> Yarn -> 放置规则
| 规则匹配顺序 | 放置规则 |
|---|---|
| 1 | 仅当池 已在运行时指定 存在时使用该池。 |
| 2 | 使用池 root.[secondary group]。 |
| 3 | 仅当池 root.[primary group] 存在时使用该池。 |
| 4 | 使用池 root.hive-read。 此规则始终满足。不会使用后续规则。 |
在配置 规则1 和 规则3 时,不要勾选:
- 在池不存在时创建池。
规则说明
规则1:保证了在Hive+Sentry的环境下,CM能够根据用户及其分组,将用户提交的任务匹配到指定的队列中。
规则2:azkaban调度用户通过在Hive Gateway上通过
hive -e "<HQL>"等方式提交任务。因此,需要在Hive Gateway所在的主机中,添加用户 hdfs, dwadmin, datadev,并为这三个用户都加上secondary group[^1]:supergroup(usermod -G supergroup <user>)规则3:Hive + Sentry 认证用户(Hue用户等),与Sentry Server上对用户的主分组一致。hive-admin分组被分配到root.hive-admin队列,hive-read分组被分配到root.hive-read队列
规则4:兜底,如果上面的规则都未满足,任务将被放置到权值低的hive-read队列
禁止Hive用户自行制定队列
Hive启用Sentry后禁用了用户模拟功能,导致所有作业均以hive用户提交,为了防止用户提交作业到其它资源池,需要禁用hive的mapreduce.job.queue.name(mapred.job.queue.name)
- 在CM Hive配置中搜索 hive-site.xml
- 追加或修改:
1<property>2<name>hive.conf.restricted.list</name>3<value>mapred.job.queue.name,mapreduce.job.queue.name</value>4</property>5```67### 运维手册89**窗口期**1011下午8点之后有调度,因此尽量在下午8点之前;暂定下午7-8点进行离线集群Yarn的维护。其中不涉及重启的部分不影响正常使用,因此可以先行修改如下配置,之后发公告留出一个小时的窗口期用于重启和验证。1213**[18:30] 发布公告**1415声明将于19点-20点进行Yarn的维护,届时Hive、Hue、Impala将不可用,Presto可正常使用1617**添加用户组**1819azkaban调度用户2021```shell22# login root@master1.cal.bgd.mjq.luojilab.com, 分发命令到Hive Gateway角色23sh ~/send_command.sh "groupadd supergroup"2425sh ~/send_command.sh "useradd hdfs"26sh ~/send_command.sh "useradd dwadmin"27sh ~/send_command.sh "useradd datadev"28# 添加azkaban调度用户secondary group29sh ~/send_command.sh "usermod -G supergroup hdfs"30sh ~/send_command.sh "usermod -G supergroup dwadmin"31sh ~/send_commasupergrouph "usermod -G supergroup datadev"
Hive + Sentry 认证用户
- 在对用户改动之前,先在Hue中完成对用户及其组的 新增/修改/删除
- 登录到Hive Server2:
1 | # login root@mg03.cal.bgd.mjq.luojilab.com, 在Hive Server2角色中调整Hive+Sentry用户和组 |
2 | cd /root/sentry/ |
3 | # sh adduser.sh <user> <group> :添加/修改用户到组, 组可用值: hive-admin, hive-read |
4 | # sh deleteuser <user>: 删除用户 |
修改
[19:00] 重启
影响范围:
- Yarn
- Hue
- Impala
- Hive
- Oozie
- YARN
[19:00-20:00] 验证
用例1:
在hive-read组提交了几个大任务的条件下,azkaban调度用户通过Hive Gateway提交任务。观察azkaban调度用户能否获得足够的资源。
- 登录Hive Gateway,做好使用azk用户提交任务的准备
- 通过脚本,使用hive-admin和hive-read组的用户名向hive发送SQL,创建几个大任务
- 在Hive Gateway上使用azk用户提交任务
用例2:
使用azkaban调度用户,在hive -e "<HQL>" 的 HQL 中设定 mepreduce.queue.name和mepred.queue.name
容量调度器(Deprecated)
由于我罗使用了Sentry认证,而Sentry底层全部使用hive用户并且关闭了模拟(impersonate),故而。
配置详解
公共配置
Overview
为了便于管理用户提交的任务,因此将用户分组,提交任务时按分组提交到对应的队列中。具体规则如下:
配置
1 | <property> |
2 | <name>yarn.scheduler.capacity.maximum-applications</name> |
3 | <value>10000</value> |
4 | <description>队列容量,包含状态为Pending和Running的application</description> |
5 | </property> |
6 | <property> |
7 | <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> |
8 | <value>100</value> |
9 | <description>集群中用于运行application master的资源占比。可用于控制application的并发数。</description> |
10 | </property> |
11 | <property> |
12 | <name>yarn.scheduler.capacity.resource-calculator</name> |
13 | <value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value> |
14 | <description>计算资源数量的具体实现。DominantResourceCalculator: 内存,CPU;DefaultResourceCalculator: 内存。</description> |
15 | </property> |
16 | <property> |
17 | <name>yarn.scheduler.capacity.queue-mappings</name> |
18 | <value>g:supergroup:supergroup,g:hive-admin:hive-admin,g:hive-read:hive-read,g:default:hive-read</value> |
19 | <description>用户/组 与 队列的对应关系。格式: [u or g]:[name]:[queue_name][,next_mapping]*</description> |
20 | </property> |
21 | <property> |
22 | <name>yarn.scheduler.capacity.queue-mappings-override.enable</name> |
23 | <value>true</value> |
24 | <description>确保用户提交的任务被放入指定的队列中。</description> |
25 | </property> |
26 | <property> |
27 | <name>yarn.scheduler.capacity.root.state</name> |
28 | <value>RUNNING</value> |
29 | <description>yarn.scheduler.capacity.{queue_path}.state。可用于启停指定queue_path的队列 |
30 | </description> |
31 | </property> |
将root队列分为default, admin队列
1 | <property> |
2 | <name>yarn.scheduler.capacity.root.queues</name> |
3 | <value>supergroup,default</value> |
4 | <description>容量调度器中,root队列下必须有一个名为default的队列</description> |
5 | </property> |
supergroup队列配置
1 | <property> |
2 | <name>yarn.scheduler.capacity.root.supergroup.capacity</name> |
3 | <value>80</value> |
4 | <description>默认队列容量</description> |
5 | </property> |
6 | <property> |
7 | <name>yarn.scheduler.capacity.root.supergroup.maximum-capacity</name> |
8 | <value>95</value> |
9 | <description>最大队列容量</description> |
10 | </property> |
11 | <property> |
12 | <name>yarn.scheduler.capacity.root.supergroup.minimum-user-limit-percent</name> |
13 | <value>30</value> |
14 | <description>每个用户的最低资源保证</description> |
15 | </property> |
16 | <property> |
17 | <name>yarn.scheduler.capacity.root.supergroup.user-limit-factor</name> |
18 | <value>100</value> |
19 | <description>每个用户可用的最大资源占比</description> |
20 | </property> |
21 | <!-- 已通过用户组映射限定用户提交任务到指定队列,无需配置 |
22 | <property> |
23 | <name>yarn.scheduler.capacity.root.supergroup.acl_submit_applications</name> |
24 | <value>hdfs,dwadmin,datadev</value> |
25 | <description>只允许hdfs,dwadmin,datadev三个用户向supergroup队列提交任务</description> |
26 | </property> --> |
default队列配置
1 | <property> |
2 | <name>yarn.scheduler.capacity.root.default.queues</name> |
3 | <value>hive-admin,hive-read</value> |
4 | <description>root.default队列分为hive-admin,hive-read两个子队列</description> |
5 | </property> |
6 | <property> |
7 | <name>yarn.scheduler.capacity.root.default.capacity</name> |
8 | <value>20</value> |
9 | <description>默认队列容量</description> |
10 | </property> |
11 | <property> |
12 | <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> |
13 | <value>60</value> |
14 | <description>最大队列容量</description> |
15 | </property> |
16 | |
17 | <property> |
18 | <name>yarn.scheduler.capacity.root.default.hive-admin.capacity</name> |
19 | <value>60</value> |
20 | <description>默认队列容量</description> |
21 | </property> |
22 | <property> |
23 | <name>yarn.scheduler.capacity.root.default.hive-admin.maximum-capacity</name> |
24 | <value>80</value> |
25 | <description>最大队列容量</description> |
26 | </property> |
27 | <property> |
28 | <name>yarn.scheduler.capacity.root.default.hive-admin.minimum-user-limit-percent</name> |
29 | <value>30</value> |
30 | <description>每个用户的最低资源保证</description> |
31 | </property> |
32 | <property> |
33 | <name>yarn.scheduler.capacity.root.default.hive-admin.user-limit-factor</name> |
34 | <value>80</value> |
35 | <description>每个用户可用的最大资源占比</description> |
36 | </property> |
37 | <property> |
38 | <name>yarn.scheduler.capacity.root.default.hive-read.capacity</name> |
39 | <value>40</value> |
40 | <description>默认队列容量</description> |
41 | </property> |
42 | <property> |
43 | <name>yarn.scheduler.capacity.root.default.hive-read.maximum-capacity</name> |
44 | <value>60</value> |
45 | <description>最大队列容量</description> |
46 | </property> |
47 | <property> |
48 | <name>yarn.scheduler.capacity.root.default.hive-read.minimum-user-limit-percent</name> |
49 | <value>30</value> |
50 | <description>每个用户的最低资源保证</description> |
51 | </property> |
52 | <property> |
53 | <name>yarn.scheduler.capacity.root.default.hive-read.user-limit-factor</name> |
54 | <value>60</value> |
55 | <description>每个用户可以使用的最大资源占比</description> |
56 | </property> |
57 | <!-- 已通过用户组映射限定用户提交任务到指定队列,无需配置 |
58 | <property> |
59 | <name>yarn.scheduler.capacity.root.default.hive-admin.acl_submit_applications</name> |
60 | <value>usera,userb,userc</value> |
61 | <description>可以向root.default.hive-admin提交任务的用户</description> |
62 | </property> |
63 | <property> |
64 | <name>yarn.scheduler.capacity.root.default.hive-read.acl_submit_applications</name> |
65 | <value>*</value> |
66 | <description>所有人都可以向root.default.hive-read</description> |
67 | </property> --> |
运维手册
窗口期
下午8点之后有调度,因此尽量在下午8点之前;暂定下午7-8点进行离线集群Yarn的维护。其中不涉及重启的部分不影响正常使用,因此可以先行修改如下配置,之后发公告留出一个小时的窗口期用于重启和验证。
[18:30] 发布公告
声明将于19点-20点进行Yarn的维护,届时Hive、Hue、Impala将不可用,Presto可正常使用
修改调度器配置
修改 “容量调度程序配置高级配置代码段”,添加2.1. 配置详解中提到的配置
修改用户分组
假设当前用户组映射的具体实现为 org.apache.hadoop.security.ShellBasedUnixGroupsMapping,因此用户组映射关系基于Name Node所在的操作系统用户组设置[^2]。

首先在Hue管理用户界面配置用户组映射,然后登录如下主机操作:
- master1.cal.bgd.mjq.luojilab.com (NN)
1 | # 创建用户组映射 |
2 | hdfs: supergroup |
3 | dwadmin: supergroup |
4 | datadev: supergroup |
5 | |
6 | usera: hive-admin |
7 | userb: hive-admin |
8 | userc: hive-admin |
9 | |
10 | xxxx1: hive-read |
11 | xxxx2: hive-read |
切换调度器
修改Scheduler 类:
-
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
-
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler
-
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
[19:00] 重启
影响范围:
- Yarn
- Hue
- Impala
- Hive
- Oozie
- YARN
[19:00-20:00] 验证
如 1.2.5. 验证
是否重启?
- 需要重启:修改了yarn-site.xml等其他组件依赖的配置。
- 例如:切换yarn的资源调度器
- 无需重启,需要刷新集群:修改其他组件不依赖的配置。
- 不切换yarn的资源调度器,而是仅仅修改队列配置、用户组映射等调度器具体配置时
总结
本文根据对 CM 动态资源池以及Yarn的公平/容量调度器的调研和实验结果,给出了两种调度资源管理策略,并最终确定下我罗通过CM 动态资源池、Yarn的公平容量调度器、Hive+Sentry用户认证的方式,实现队列资源隔离、队列资源可伸缩、队列访问控制。
参考资料
[^1]: 因为 hdfs 等用户所在的主组另有他用,不能覆盖。
[^2]: 此外,如果启用了HDFS的HA,除了Name Node之外,用户组映射配置也需要同步到Name Node Standby节点。