背景介绍
现在 ElasticSearch 大量应用在搜索领域,开发者可以通过其提供的多样的查询api达到希望的搜索效果,而且Elasticsearch版本也一直在不断迭代,以满足开发者的需要。但是,实际开发过程中,可能需要将搜索和自己的业务场景进行结合,来达到自定义的排序、搜索规则。Elasticsearch针对这种情况,提供了插件的功能,可以这么说,如果能够学会使用插件,那我们就有了自由扩充ELasticsearch功能的手段,对搜索的掌控力就能提升一个档次。
Es插件分类
插件作为ES的架构中的重要一环,ES为其开放了足够多的接口使开发者可以实现自定义的功能需求,其共支持下面十种插件,AnalysisPlugin,ScriptPlugin,SearchPlugin这三个常用插件我们在后面会更详细的讲解
1、AnalysisPlugin
分析插件,用于开发者开发额外的分析功能来增强Elasticsearch自身分析功能的不足,medcl大佬的ik分词插件相信大家都用过.
2、ScriptPlugin
脚本插件.会调用用户的脚本,其中主要是用在function_score查询中,使用自定义方法进行打分,我们熟知的painless脚本就是ScriptPlugin脚本
3、SearchPlugin
查询插件,扩展Elasticsearch的查询功能,es 的search功能功能十分强大,有了SearchPlugin我们可以在search中增加更多查询方法,我们后续可能会在此基础上增加很多令人兴奋的查询。例如根据用户购买的书籍查询与用户相似的其他用户,例如结合模型对搜索词进行expanding。
4、ActionPlugi
Restful API命令请求插件,如果Elasticsearch内置的命令如_all,cat,/cat/health等rest命令无法满足需求,开发者可以自己开发需要的rest命令,例如希望看到某个分词器的词表的命令。
5、ClusterPlugin
集群管理插件,用于加强自定义对集群的管理功能,该插件可以用来扩展allocation机制,例如在进行分片选择的时候如果我们可能倾向于一些机器,
6、DiscoveryPlugin
自定义发现插件,目前是使用zen协议来进行。
7、IngestPlugin
预处理插件,在数据索引之前进行预处理,例如根据用户ip来增加地理信息的geoip Processor Plugin
8、MapperPlugin
映射插件,加强ES的数据类型.比如增加一个attachment类型,里面可以放PDF或者WORD数据
9、NetworkPlugin
网络传输插件插件,
10、RepositoryPlugin
存储插件,提供快照和恢复
ES插件加载过程
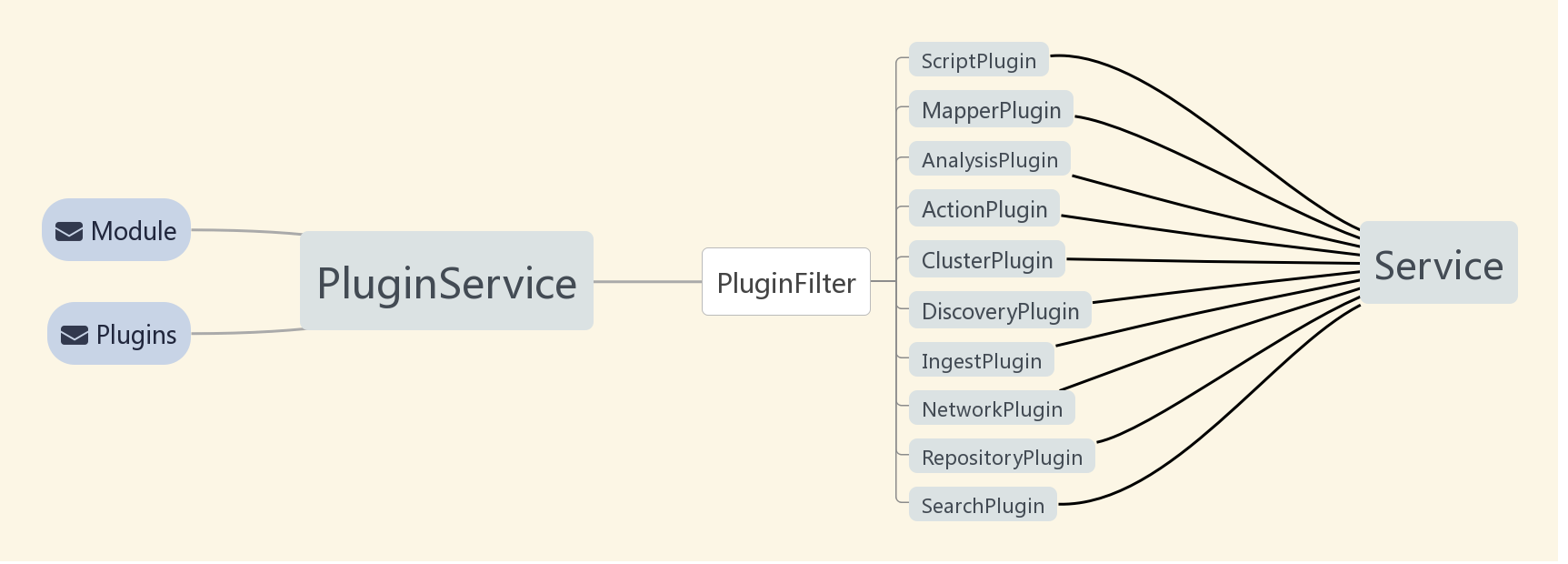
- 插件的加载时机是在节点启动创建的时候中会扫描Elasticsearch的安装目录下的plugins和module的插件列表,并通过PluginService进行解析插件。
- PluginFilter是用来识别plugin类别的一个方法,通过每个插件实现的接口将所有插件分类并分发给Elasticsearch不同的服务组件进行注册。
- 在node不同的服务启动过程中会读取每个和自己相关的组件进行扩展,最终插件都会形成服务提供给集群使用(比如ScriptPlugin最终在ScriptService提供服务,SearchPlugin最终会在searchTransportService中提供服务)
plugin-descriptor.properties
PluginService 加载插件的元信息会从该文件中进行读取,所有插件都需要这个文件,下面两个配置比较重要,如果es版本不一致会加载失败。
1 | name=${project.name} |
2 | description=${project.description} |
3 | version=${project.version} |
4 | classname=${elasticsearch.plugin.classname} 插件入口 |
5 | java.version=1.8 |
6 | elasticsearch.version=${elasticsearch.version} 插件对应es版本 |
Example:AnalysisPlugin
这里我们就使用十分流行的ik分词来解释,ik是一款十分流行的中文分词器,其能支持粗细力度的中文分词,其就是一款基于AnalysisPlugin实现的插件
IK分词类图
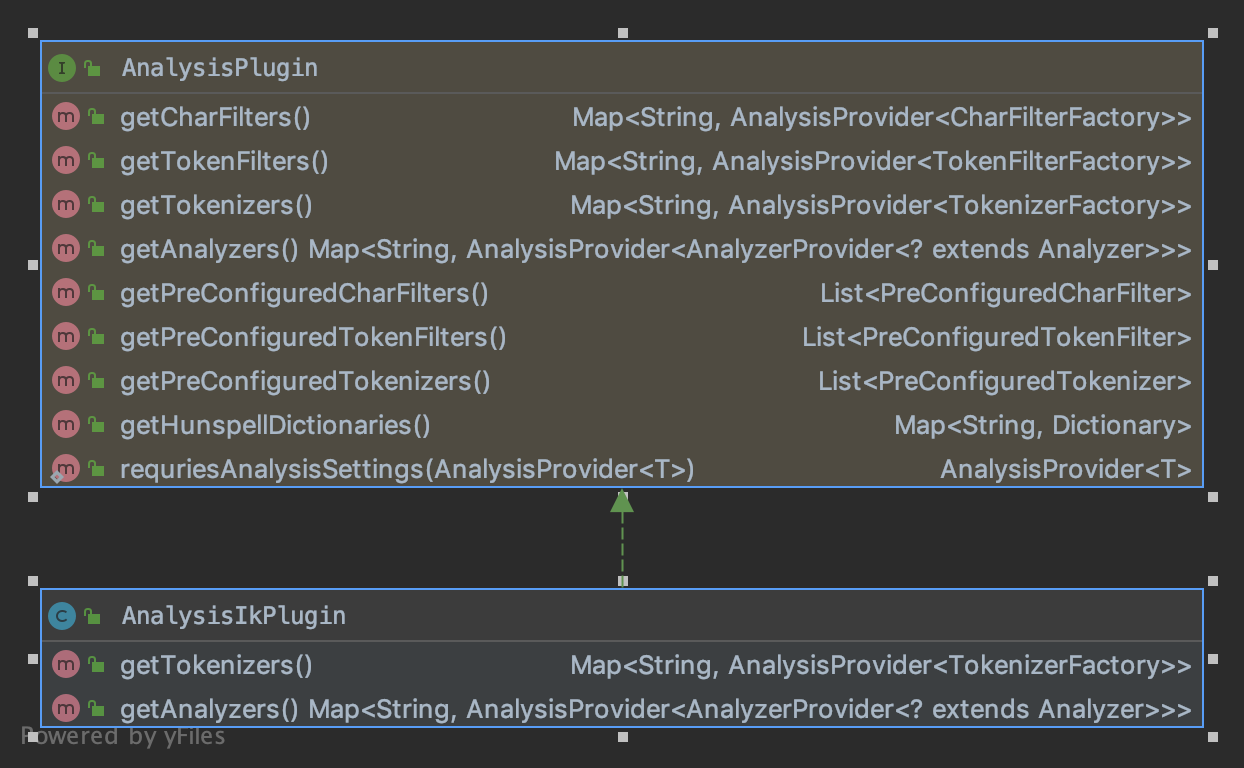
我们可以看到ik分词主要实现了接口中的getTokenizers()和getAnalyzers(),其调用流程如下:
- 其在Node初始化时就会将pluginService的中的AnalysisPlugin插件加载到AnalysisModule中。
- 在AnalysisModule中进行分词器和分词器的注册。
- 在注册的过程其实就是将AnalysisIkPlugin的getTokenizers和getAnalyzers返回的分析器和分词器放入key是名称,value是工厂类的map中。
我们这里只看分词器,实际上被注册到分词组中的是一个工厂类,其返回一个继承自Tokenizer的IK Tokenizer,这里最核心的就是incrementToken(),其会进行循环词语切分,最终将词语切分完毕,如果自定义分词器,此处就是决定分词的方法。
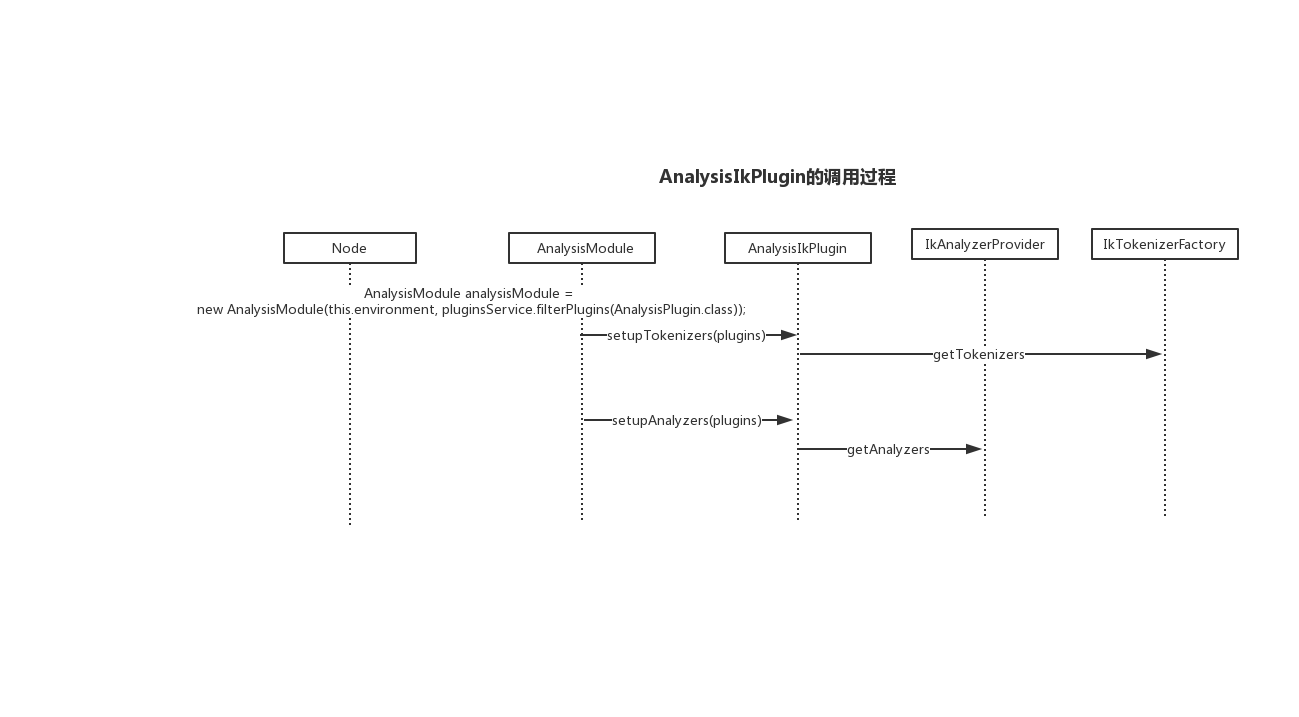
自定义分词器步骤
如果我们要实现我们自己的分词器的话其实只要进行如下几步
继承AnalysisPlugin接口和Plugin接口,实现其中获得工厂类的getTokenizers。
实现自定义分词的工厂类方法,其要继承自AbstractTokenizerFactory,实现create来返回自定义测分词类。
实现自定义分词类其继承自Lucene的Tokenizer抽象类,将实现incrementToken方法。
最终将程序中加入plugin-descriptor.properties组价描述文件,打包放入plugin文件中即可。
我们的实践
ScriptPlugin
现状
容错在搜索中十分常见,但我们经过对搜索无结果日志分析发现对于有很大一部分错误都发生在拼音相同但字写错的了情况。
无结果日志
1 | 事件 总数 平均 20190624 20190625 20190626 |
2 | A->总次数,马徐俊 8 1.1429 0 0 0 |
搜索词日志
1 | 搜索关键词 搜索次数 搜索人数 |
2 | 逻辑思维 168 137 |
问题及解决
所以我们希望能够实现拼音级别的容错,然后又不希望字错的字太多,就使用如下DSL
1 | {"query":{ |
2 | "bool":{ |
3 | "filter":[ |
4 | { |
5 | "multi_match":{ |
6 | "query":"{{.Query}}", |
7 | "analyzer":"standard", |
8 | "fields":[ |
9 | "title.standard", |
10 | "author.standard" |
11 | ], |
12 | "minimum_should_match":"50%" |
13 | } |
14 | }, |
15 | { |
16 | "bool":{ |
17 | "should":[ |
18 | { |
19 | "match_phrase":{ |
20 | "author.pinyin":{ |
21 | "query":"{{.Query}}", |
22 | "analyzer":"pinyin" |
23 | } |
24 | } |
25 | }, |
26 | { |
27 | "match_phrase":{ |
28 | "title.pinyin":{ |
29 | "query":"{{.Query}}", |
30 | "analyzer":"pinyin" |
31 | } |
32 | } |
33 | } |
34 | ] |
35 | } |
36 | } |
37 | ]} |
38 | } |
39 | } |
但如此便存在一个问题,其匹配到了_dujia_的拼音,又匹配到了其中一半的字家,所以其能被命中返回,如下所示
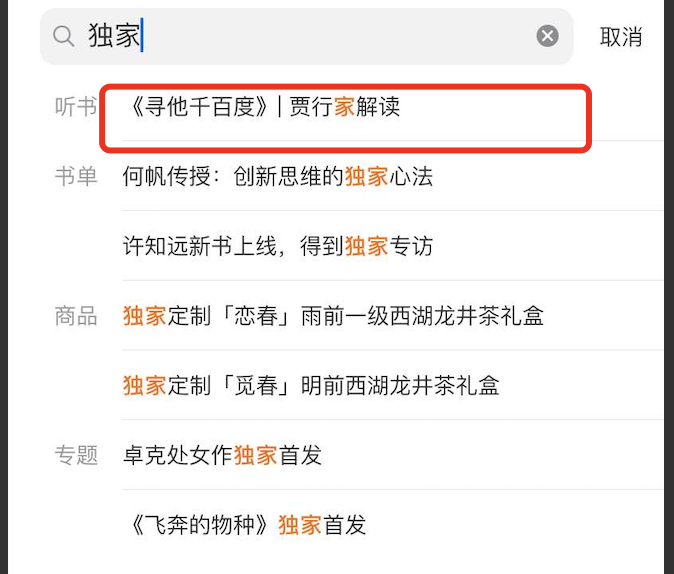
所以我们新增了一个组件用以限制查询词的长度,太短的词不应进行容错,而且在词变长就不会出现上述问题。其继承自ScriptPlugin,并且实现了自定义的打分逻辑,如果限制的查询语句超过少于限制的长度则直接返回-1分,否则根据配置返回固定的分或者ES打出的分。
主要代码逻辑
1 | public SearchScript newInstance(LeafReaderContext context) throws IOException { |
2 | return new SearchScript(p, lookup, context) { |
3 | public double runAsDouble() { |
4 | if(query.length()<length){ |
5 | return -1d; |
6 | } |
7 | return Integer.MIN_VALUE==constant_score?getScore():constant_score; |
8 | } |
9 | }; |
10 | } |
1 | // 新增语句 |
2 | { |
3 | "script_score": { |
4 | "script": { |
5 | "source": "limit_query", |
6 | "lang": "limit_query_length", |
7 | "params": { |
8 | "query": "{{.Query}}", |
9 | "length": "3", |
10 | "constant_score": "1" |
11 | } |
12 | } |
13 | } |
14 | } |
思考
其实这里我们可以做的更多
- 在lookup中我们可以拿到每个doc的_source字段
- 在context中我们可以拿到全局的mapping,setting等信息
- 在score中可以拿到本来的分数
SearchPlugin
现状
我们在实现长句搜索的时候可以使用 more-like-this,其原理大体就是将like的语句进行分词后然后依照BM25 选出在该字段中得分最高的n个词语,然后将原本查询的长语句变成了多个重要词的查询。
问题及解决
从morelike中提取出来的词相距距离太长依旧可以召回,相信熟悉Es的同学都知道ES有match_phrase的语法,其中的slop可以限制词的距离,所以我们希望能够实现一个增加词距离的morelike语句,我们称其为more_like_this_phrase,要使es能够识别我们的组件实现SearchPlugin接口,并返回build的类和解析查询的方法就可以了。
1 | public class MoreLikeThisPharseSearchPlugin extends Plugin implements SearchPlugin { |
2 | |
3 | @Override |
4 | public List<QuerySpec<?>> getQueries() { |
5 | return singletonList(new QuerySpec<>(MoreLikeThisPharseQueryBuilder.NAME, MoreLikeThisPharseQueryBuilder::new, MoreLikeThisPharseQueryBuilder::fromXContent)); |
6 | } |
7 | |
8 | } |
由于我们是基于more_like_this进行的修改,所以主要修改的解析体和创建lucene query的逻辑
解析方法 MoreLikeThisPharseQueryBuilder::fromXContent
加入解析slop的方法,将slop存到MoreLikeThisPharseQuery对象中
创建lucene查询 createQuery
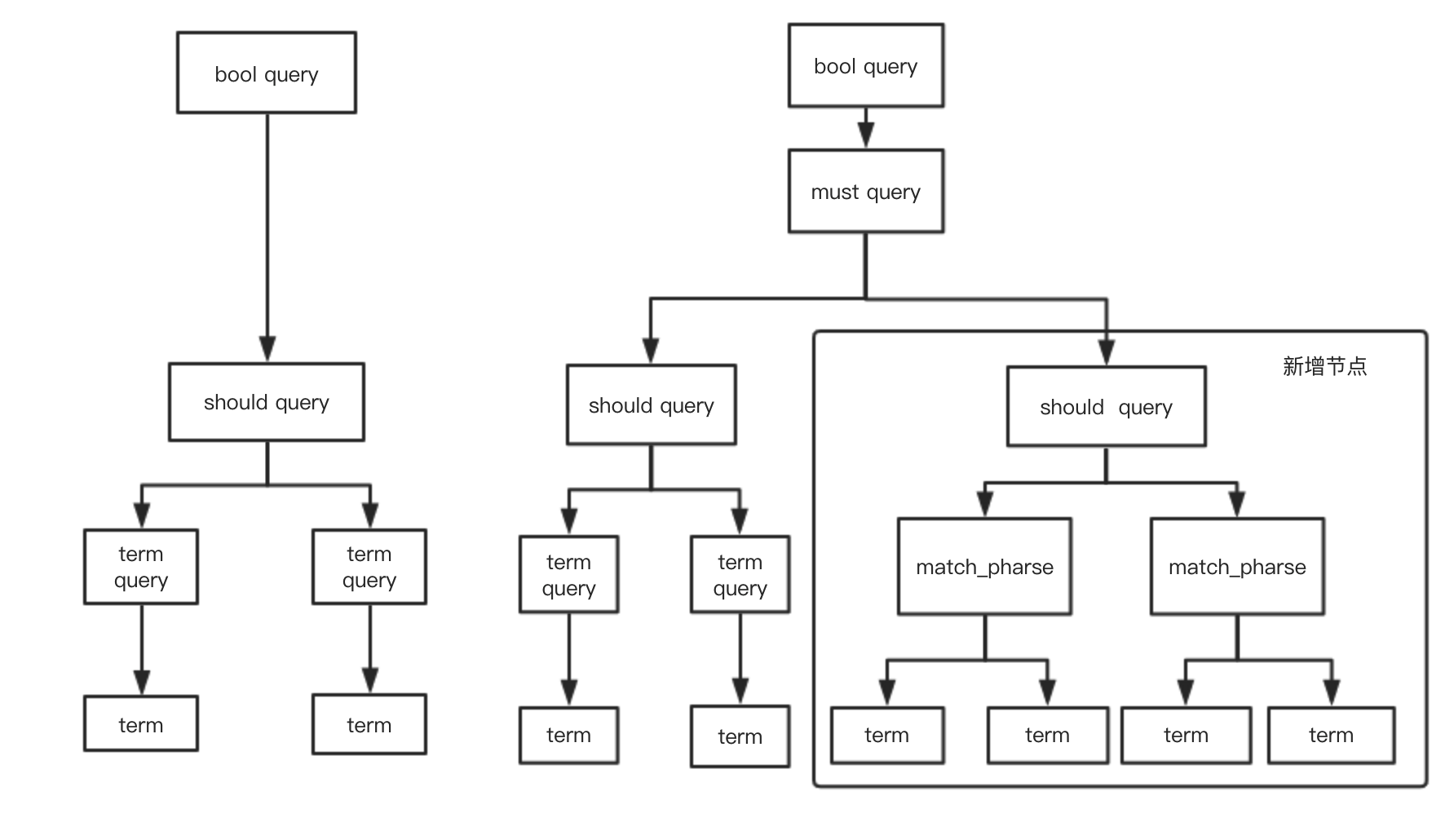
more_like_this_phrase 在原基础上进行了修改,从多个term query抽取出最少需要匹配到的个数(如果minishouldmatch有配置则使用minishouldmatch的个数,只需匹配任意一个即可),将所抽出的m个 数的词中任意挑选 n个词进行match_phrase+slop的查询
原lucene 查询结构
总结
插件是解决复杂自定义打分排序逻辑的利器,后面我们会依赖插件实现更多的打分召回策略,为用户提供更好的搜索服务。
[1]: ElasticSearch Plugins and Integrations
[2]: Elasticsearch源码分析 Plugin组件加载